[论文解读]World of Bits: An Open-Domain Platform for Web-Based Agents
论文地址:World of Bits: An Open-Domain Platform for Web-Based Agents
摘要
虽然模拟游戏环境极大地加速了强化学习方面的研究,现有的环境在计算机视觉以及自然语言处理的任务上缺乏开放域的真实感。这些任务在自然、有机的环境下,对人造的物体进行操作。为了促进这些环境中强化学习的研究,我们提出了比特世界(World of Bits, WoB)。在这个平台上,智能体通过进行低层的键盘鼠标操作完成互联网上的任务。两个主要的挑战是:
- 建立一个基于 Web 的任务的多样的集合。
- 确保这些任务有一个被明确定义的奖励结构,并且在网络变化无常的情况下,是可重复的。
为了解决这个问题,我们提出了一个方法论,在这个方法论中:众包工作者创建被自然语言定义的问题,并且使用键盘和鼠标在真实网站上提供一个如何解决问题的演示;HTTP 交互数据被缓存下来,以建立一个可复现的网站离线近似。最后,我们展示通过行为克隆和强化学习训练的智能体可以完成大量的基于 Web 的任务。
研究背景
过去几年内,研究者们在创造能够和越来越复杂的环境进行交互的智能体这一方面取得了重大进展。在这个过程中,核心学习算法和用于提取动态特征以及测试算法的模拟环境同样重要。但是,现在的模拟环境本质上是被限制了的:在这样的环境中,智能体从未体验过真实世界中纯粹的多样体验,这意味着它们丢失了重要的语义知识,而这些知识对智能的发展十分关键。
文章贡献
本文提出了 WoB ,将 Web 作为一个拥有丰富的开放域环境的源。在这些环境中,智能体观察文档对象模型(Document Object Model, DOM)以及对应的渲染图像;并通过鼠标与键盘操作解决 Web 任务。将 Web 作为学习平台有以下三个优点:
- 开放域:因为智能体直接与网页 UI 进行交互,不需要设计特殊的 API,因而网站成为了可以提供丰富的学习环境与应用域的源。
- 开源:WoB 是数字化的,支持快速迭代与大规模缩放。同时由于网页源代码是开源的,很容易进行检查与动态调整。
- 容易收集数据:因为智能体的动作和人类的动作是一样的——键鼠操作,因此可以通过众包工作的方式,雇人演示 Web 工作的解决方案,从而大规模收集数据。
问题描述
Web 环境
将 Chorme 浏览器封装入 Docker 容器中,暴露 Gym 界面以让智能体进行交互。
在每个时间步,智能体观测到的状态包括:原始屏幕像素 (屏幕宽度、屏幕长度、RGB 三个通道的值);DOM 文档 ;以及一个奖励信号 (标量)。其中, 中的每一个元素都用一个四元组 描述,表示其边界框(bounding box)。
智能体的输出应当是一个动作序列,这些动作可以包括:
- 一个键盘事件,如按下
k键。 - 一个鼠标事件,如保持鼠标左键按下,将鼠标移动到位置 。
之后,智能体会获得奖励 ,这个奖励由具体任务决定。
简约 Web 任务:MiniWoB

为了简化任务和环境,MiniWoB 的环境只有 112 行 HTML/CSS/JavaScript 代码。每个 MiniWoB 环境的 HTML 页面宽 160 个像素,高 210 个像素。其中最顶端的 50 个像素(黄色背景)包括了任务的自然语言描述,而下方的 的区域用于交互。
MiniWoB 的奖励在 (失败)到 (成功)之间分布,并且和时间是线性相关的,以鼓励智能体快速完成任务。
实时 Web 任务:FormWoB
FormWoB 的目的在于将网站转换成 Web 任务。因为网站每时每刻都在发生改变,为了不在智能体训练的时候向网站发送垃圾请求,我们通过使用代理录制智能体与网站之间的 HTTP 请求与回复,来建立网站的离线近似。
奖励函数也通过请求进行定义,表单填充任务需要智能体最后向服务器发送一个包含若干个键值对的请求。因此奖励就被定义为:和人类演示最后发送的键值对匹配的键值对的比例。
如果智能体进行了一个操作,产生了一个在人类演示中从未出现的请求,那么这轮训练会被立刻终止,智能体所获得的奖励为 。这为智能体与真实网站交互提供了一个奖励的下限(假设所有奖励都是非负的),因为所有的导致缓存丢失的结果都会获得最小的奖励。
最后的 FormWoB benchmark 为: 在四个航班预定网站上进行了应用(United, Alaska, AA, and JetBlue)。在每个网站上,智能体必须填好一个表单并且点击提交按钮。填写表单的过程需要很多不同的交互技能,如使用自动补全输入城市、使用日期选择器等等。对于每个网站,请求模板都需要以下四项:出发地、目的地、出发时间、返回时间。机场的名字从 11 个主要的美国城市中采样,日期从 2017 年三月进行采样。对于每个请求模板,创建了 100 个不同的实例,并且对于每个请求,录制了一轮用户演示。
大规模众包 Web 任务:QAWoB
QAWoB 的提出在于充分利用互联网的大规模与多样性。作为一个能够生成 Web 任务,而不需要人工为每个任务指定奖励函数的更具有扩展性的方法,其关键在于将 Web 任务建模成问题回答任务,并且通过众包工作来征求问题。
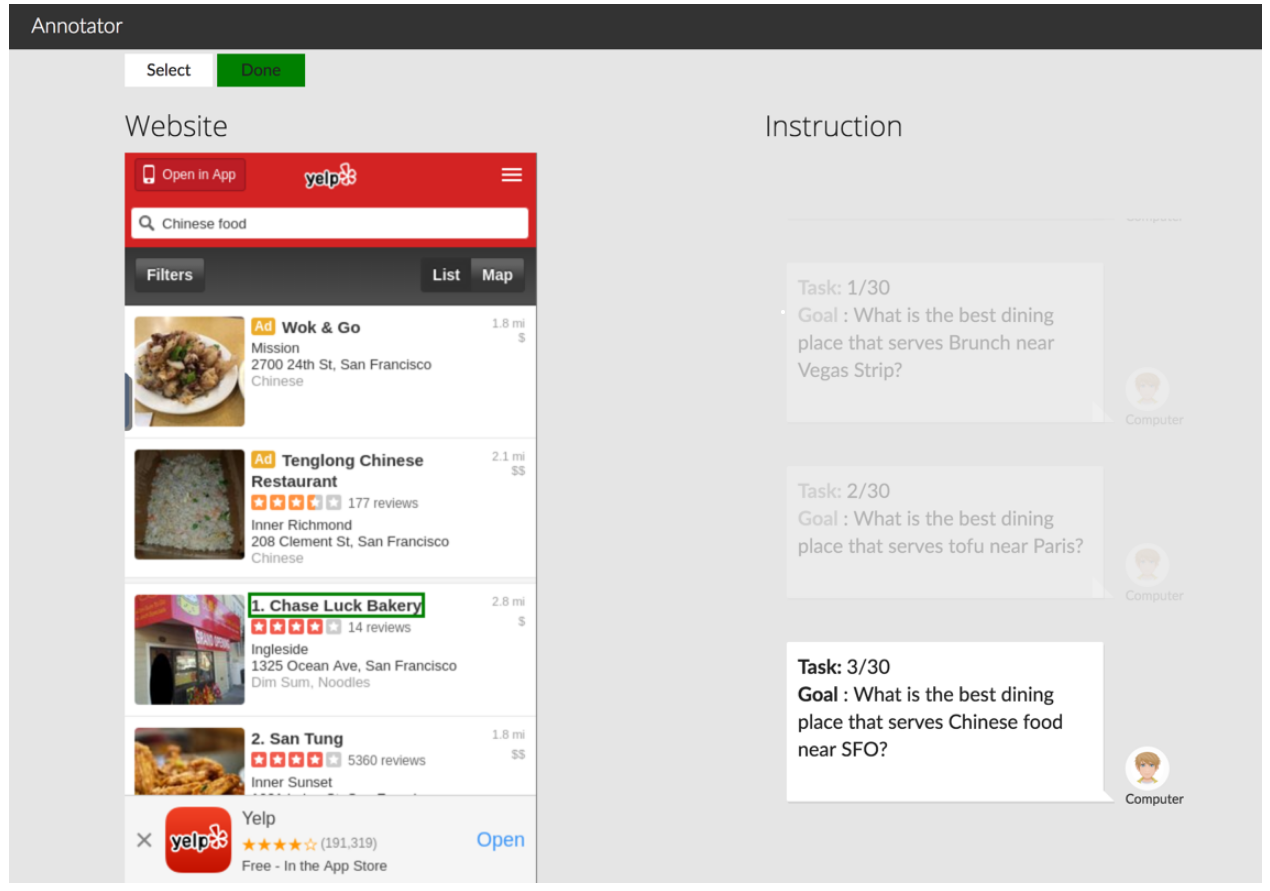
如上图所示,众包工作主要包括两个步骤:
- 一个工作者提供一个网站和一个提问模板(如:【地点】附近最便宜的卖【食物】的餐厅是什么?)同时也需要为模板中的每一个插槽提供一些可选择的填入值(如【北京/上海】、【汉堡/冰淇淋】等等)。
- 接下来,一个工作者会通过演示界面回答步骤一中提出的问题,并且标记出包含答案的 DOM 元素。
在这个场景下,只有当智能体点击了标记的 DOM 元素,才会获得 1 的奖励值。
在进行众包工作时,引入了两个限制:
- 提出的问题需要尽可能少的阅读理解。
- 网站应该对移动设备友好。
最后的 QAWoB benchmark 为:QAWoB 数据集拥有 521 个请求模板。大多数模板都有 2 个插槽。对于每个插槽,提供 10~100 个可选择的槽值,最终生成了 13550 个请求,其中 11650 个请求都有对应的答案。在大多数任务中,智能体需要在多个屏幕之间或者多个菜单之间导航,并且在定位答案之前需要进行搜索操作。这让纯粹的强化学习方法很难学习到这些问题的解决方式,因为随机探索很难向目标推进。
数据集中有一部分任务的完成路径被标注了,对于有很多路径完成的任务,标注只提供最短路径中的一条。
解决方法
为了建立一个可以解决 WoB 中问题的智能体,需要对状态空间和动作空间进行理想的建模。
模型
状态空间:状态空间包括彩色图像 ,DOM 文档 ,和请求 。彩色图像 的形状为 。DOM 文档是一个文本元素的列表,包括元素对应的边界框 以表示它们的位置关系。对于 MiniWoB ,请求是自然语言;对于 FormWoB 和 QAWoB ,从请求中以(模板、插槽)的形式提取出语义框架。
动作空间:动作空间包括指针位置、鼠标操作和键盘操作。这三种元素的采样都通过多项式分布进行采样。对于指针位置,从图像中的每个一位置进行采样,其取值为: ;对于鼠标操作,从五种操作中进行采样:没有操作,点击,拖拽,上滑滚轮,下滑滚轮;对于键盘操作,除了单键的按下以外,还将部分安全的组合键作为原子操作,纳入键盘的动作空间,如复制、粘贴、全选快捷键等。
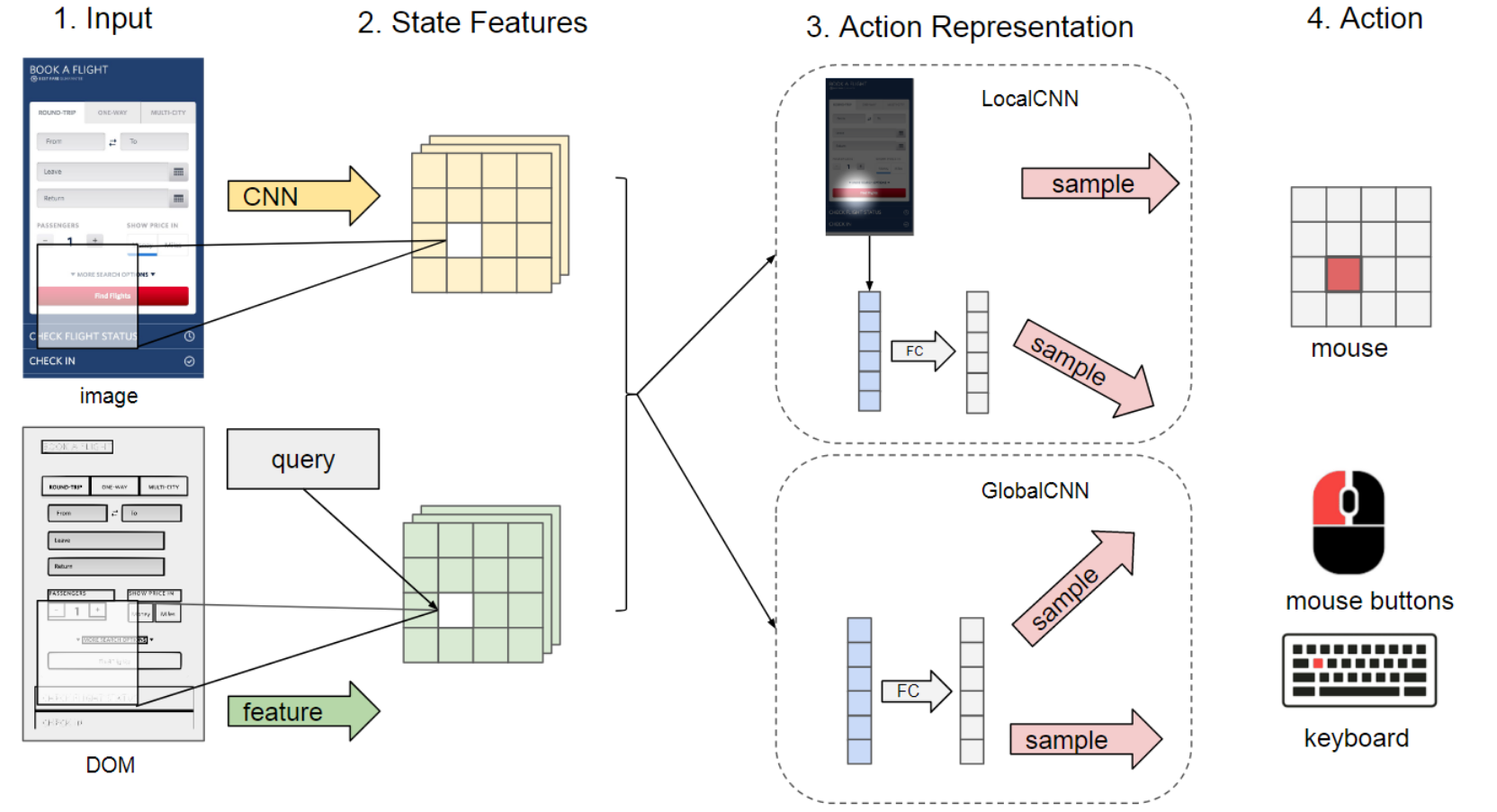
模型架构:如上图所示,对于图像,通过一个 CNN 进行特征提取;对于 DOM 文档,通过请求与 DOM 之间的匹配关系建立一个文本特征映射。接下来,两个被提取的特征被连接成为一个联合特征。基于上述处理,后续的处理有两种方式:
- GlobalCNN:展平所有特征,并将其输入到全连接层。
- LocalCNN:直觉告诉我们,单独的局部特征也足以预测下一个动作,因此通过注意力机制引导智能体关注指针所在的位置。因此指针的分布被用作为软注意力机制,以对 CNN 提取的特征取平均,将其转换为全局表示,用于预测鼠标和键盘动作。
优化
优化方式总共两种:行为克隆与强化学习。
行为克隆:因为 Web 任务有着非常长的时间窗口和非常稀疏的奖励,简单的强化学习算法很有可能会失败。因此在进行强化学习之前,先通过监督学习在人类的演示上对智能体进行预训练。在预训练的过程中,由于一个演示可能会包含大量的无用的帧,因此会先进行筛选操作,只保留关键帧。
强化学习:通过监督学习学习到的策略存在符合错误,因此通过策略梯度算法对策略进行微调。具体地,使用异步优势的 ACtor-Critic(A3C)算法,并且使用广义优势估计其优势,参数按照标准设置为 。
实验验证
MiniWoB
演示数据
对于每个 MiniWoB 环境,录制了 10 分钟的演示。不同于 FormWoB 和 QAWoB ,MiniWoB 的操作中包括了需要拖拽和悬停(触发菜单展开)的操作。因此,将演示处理为 83 毫秒一帧(1 秒 12 帧)来捕捉交互-动作对,共计约 720000 对。
通过将每个 的网格视作一个网格点(这里是为了减少可选的动作数量),可以得到一个 的网格图,加上可能的操作一共有 3 种(移动、拖拽、悬停),因此总共可能的动作有 种。
模型
在 MiniWoB 的实验中,使用了一个 6 层的前馈网络,以 的图像作为输入,将其输入到 5 个卷积层中。这些卷积层均拥有步长为 的 的滤波器,其输出通道数分别为 。接下来,对特征进行平均池化操作,并分别通过两个拥有 384 个单元的全连接层预测鼠标和键盘操作的概率。
在训练过程中,如果将之前采取的动作也输入网络,会导致网络性能下降。因为这样会导致智能体学习到像人类一样连续移动鼠标,但是这个路径通常是曲折的,这对很多环境下的探索会造成负面影响。
测试
以测试为目的,一个非常健壮的数据就是成功率(success rate, SR)。MiniWoB 中的任务被设计成:如果奖励是在 之间,那么说明任务部分成功,如果奖励是负数,那么说明任务失败。因此,给定一个奖励 的列表,成功率被定义为:
在测试过程中,将监督学习强化学习相结合的方法(SL+RL)、监督学习方法(SL)与随机(Random)的 baseline 进行对比实验。
监督学习
监督学习使用 Adam 优化器,学习率设置为 。batch size 设置为 。在损失函数的设置上,发现将点击事件和键盘事件(相较于移动事件,这两种事件更少见)的损失权重提高 10 倍会带来更好的效果。
训练完成后,使用训练好的策略在每个环境上测试十万步,并且计算成功率指标。
强化学习
以 12 帧的帧率,设置步数上限为十万步,对智能体在 12 个环境中并行进行训练,并且每隔 200 个时间步更新一次参数(batch size 为 )。使用 Adam 优化器,学习率被设置为 。
为了减轻异步训练的影响,将模型训练了三次,并选择了最优的一次。
实验结果
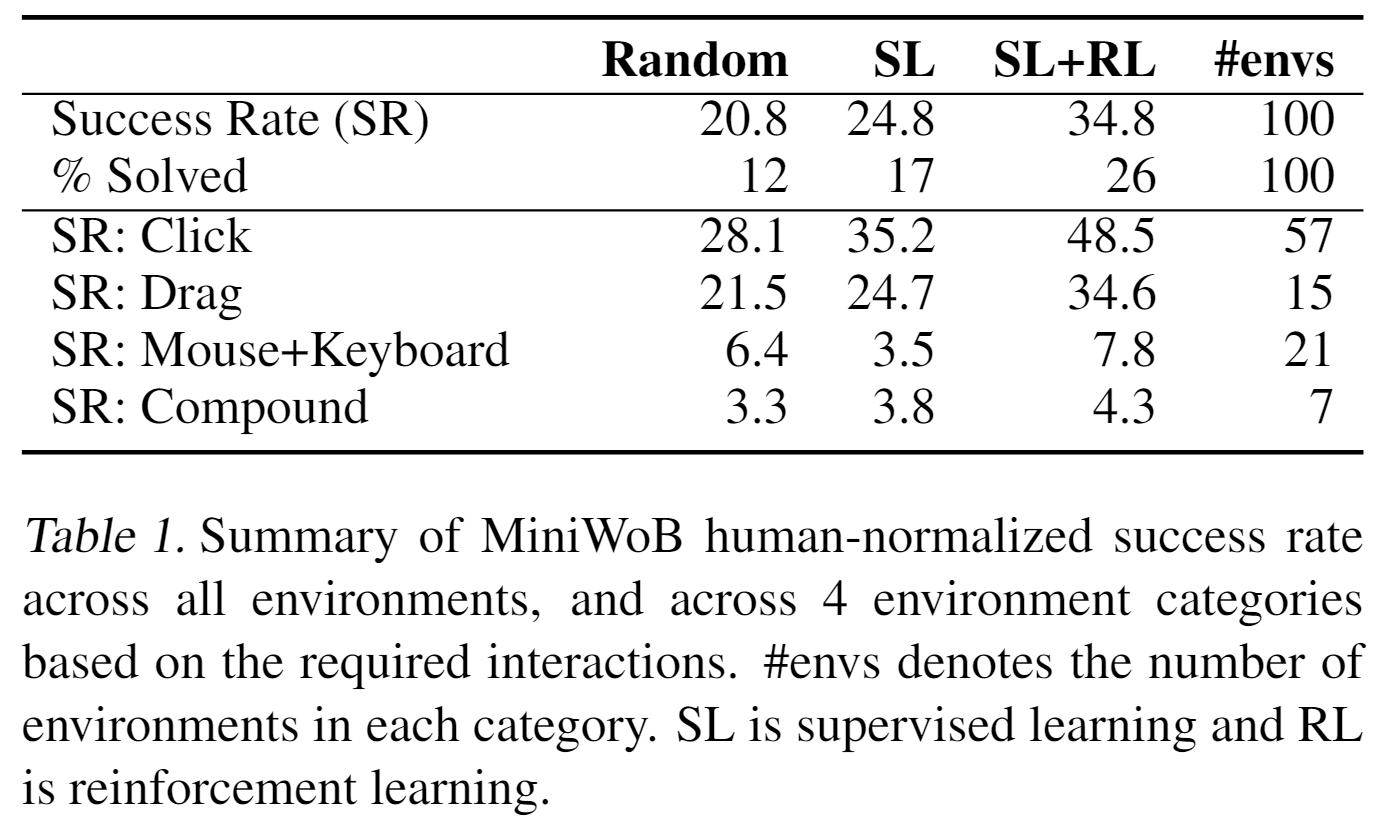
如果一个任务的成功率在 以上,就认为这个任务被解决(Solved)。
可以发现:
- 监督学习可以小幅改善策略,而强化学习的微调可以大幅改善策略。
- 大多数成功的任务都来自于需要鼠标操作(点击、拖拽)的任务,而如果任务需要键盘操作,成功率会大大下降。
- ”复合“环境是最困难的环境,因为它们综合了多种动作,实际上这些环境的成功率也是最低的。
值得注意的是:随机策略在一些环境中也能表现得很好,因为操作频率很高(12 FPS)。并且对于正确行动的奖励是随时间线性下降的。
FormWoB
环境设置
FormWoB 环境的页面大小为 。数据集包括四个航班预定网站:United、Alaska、JetBlue 精二 American 。环境的运行速度为每秒 1 帧以适应页面加载的时间。
演示数据
对于每个网站,通过 AMT 收集了 100 个(请求、演示)对。大多数交互只包括点击和输入操作。预处理之后,每一轮大约包括 30~50 个键盘或鼠标事件。整个页面被划分成 的网格,键盘事件的编码与前文动作空间中所描述的一致。
模型
整体模型与 MiniWoB 相似,均使用了一个 6 层的结构,但是移除了拖动操作。同时测试了 LocalCNN 模型,直接输出一个 的特征图,用于驱动注意力和鼠标点击事件。
对于 DOM 数据和请求数据,使用了一个简单的启发式策略将两者结合,以计算请求特征图,这个特征图标识了输入中突出的位置。具体地:将请求中的单词与 DOM 中的单词进行相似度的计算,度量指标为编辑距离。再将计算出来的相似度放在对应的 DOM 元素上(边界框中间)。例如:如果请求中包含 "From"这个单词,那么页面中任何包含 “From” 的元素在特征图中都会有更高的激活值。
对于键盘操作,如果只是把键盘操作看成一个简单的分类问题,这对智能体来说是很困难的,因为智能体必须学会在一次输入一个字母的情况下,输入完整的单词。因此,对于每一个槽值,引入一个指针,智能体只需要决定输出哪个槽的下一个字符。

如上图所示,一共有四个槽,如果智能体输出的动作序列为 K1 K1 K1 K2 K2 ,那么会依次输入 S a n (SanFrancisco 的前缀),再依次输入 N e (NewYork) 的前缀。这时,第二个槽的指针会指向 w ,而第一个槽的指针会被重置,指向 S 。
监督学习
监督学习的设置与 MiniWoB 大体相同。但是学习率被设置为 ,并且键盘事件对损失函数的贡献会有 20 倍的权重。
强化学习
对于每个环境分别进行强化学习的训练。在训练时,从请求中随机取样,并且运行速度为 8FPS 。
测试
在本次训练中,测试了模型对不同请求的泛化能力。将每个网站的任务的 80% 用于训练,20% 用于测试。首先,将测试相似度作为指标,以表示智能体对人类轨迹的建模效果。其次,分别记录智能体在训练集和测试集上能够获得的奖励。取最后三个检查点奖励的平均值作为结果。
实验结果
下图展示了 FromWoB 环境中智能体的学习曲线:
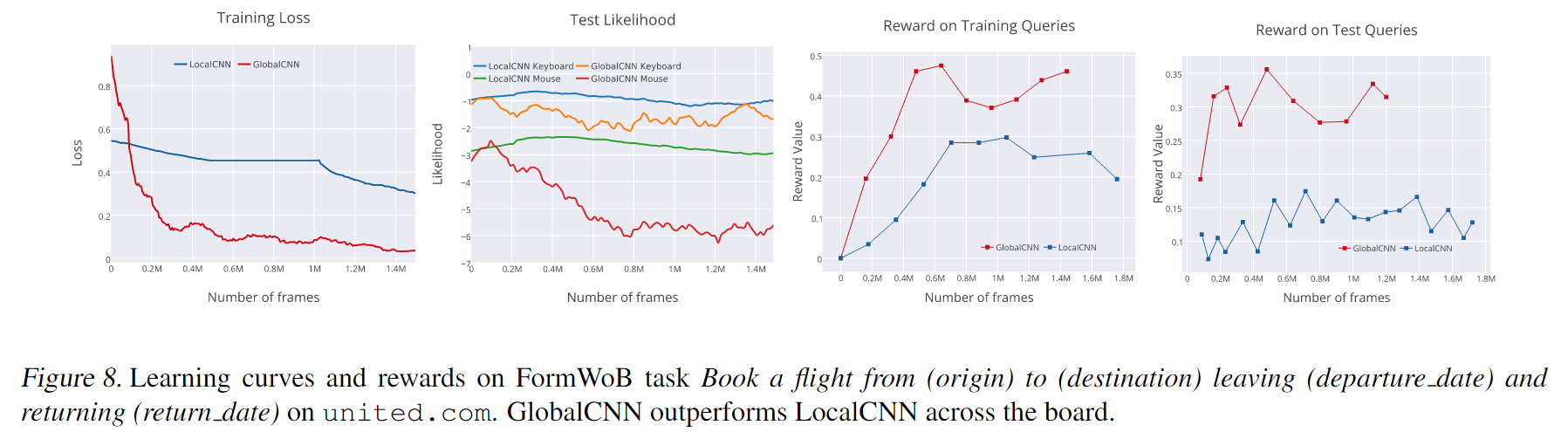
下图的前半部分展示了 FormWoB 的实验结果:
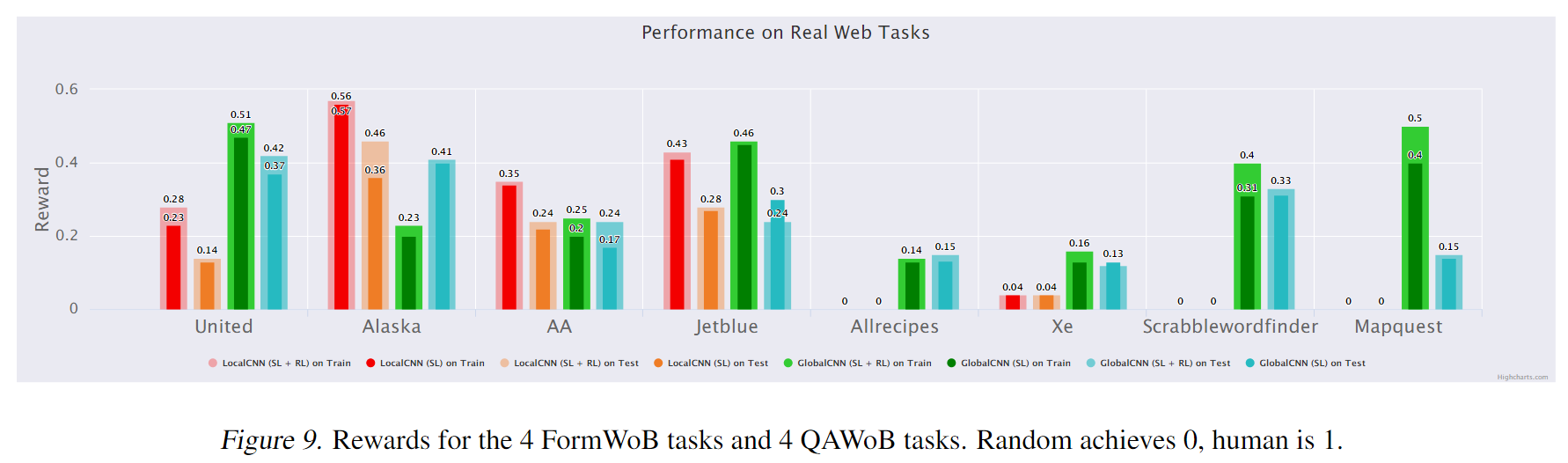
随机方法在 FormWoB 的任务中所获得的奖励为 0 ,而本文所提出的模型表现出了学习与泛化的能力。具体地,对于航班预定任务,模型在训练集上达到了人类水平的 ,在测试集上达到了人类水平的 。

对模型的注意力机制进行可视化可以发现:通过文本匹配的帮助,模型能够成功在下拉框中选择城市和正确的日期。并且在一些随机的滚动发生之后,模型依旧能集中注意力在”提交“按钮上。智能体最常见的错误模式是:如果出现了一些人类演示之外的错误(如报错信息),那么智能体很难采取动作修复错误。
QAWoB
QAWoB 的实验设置与 FormWoB 相同,测试网站包括:Xe、Allrecipes、Scrabblewordfinde 和 Mapquest 。
下图的后半部分展示了 QAWoB 的实验结果:
观察发现,LocalCNN 架构不足以处理 QAWoB 任务,而 GlobalCNN 架构要好很多。这与训练过程中,GlobalCNN() 的 loss 低于 LocalCNN() 是一致的。推测原因为:LocalCNN 中引入的归纳偏差会使其无法拟合有很多噪声的人类演示。