[论文解读]Reinforcement Learning on Web Interfaces using Workflow-Guided Exploration
论文地址:Reinforcement Learning on Web Interfaces using Workflow-Guided Exploration 。
摘要
强化学习的智能体通过试错来学习,但是当奖励十分稀疏,智能体不能发现成功的动作序列时,学习就会停滞不前。这在训练深度强化学习智能体完成基于 Web 的任务时是一个难以忽视的问题,如订机票,回复邮件等任务。在这些任务中,通常一个错误就会毁了整个动作序列。一个常见的补救措施是对智能体进行预训练,让其模仿人类的演示,但是这又会导致过拟合。因此,我们建议使用演示来限制探索。从每个演示中,我们归纳出高级“工作流”,它约束了每个时间步中被允许的动作,以使其和演示中的动作相似(如:第一步,点击一个文本框;第二步,输入一些文字)。然后我们的探索策略会学习去判别成功的工作流,并且从这些工作流中采样动作。工作流修剪掉了不好的探索方向,提升了智能体探索奖励的能力。我们使用我们的方法训练一个理想的神经策略模型,用于解决半结构化的网站上的问题,并且在一套 Web 任务上进行测试,包括最近的 WoB 测试环境。我们得到了新的最先进的结果,并且表明基于工作流的探索比动作克隆将采样效率提升了百倍。
研究背景
研究者们对训练强化学习智能体直接通过控制浏览器来使用互联网这一任务非常感兴趣,这能够扩展 AI 个人助手的能力。然而现在的 AI 助手只能与机器可读的 API 进行交互,而不能与更多的人类可读的 Web 界面进行交互。
强化学习智能体可以通过试错来学会使用人类可读的 Web 界面,但是当任务的奖励十分稀疏时,学习过程会非常漫长,因为大量的缺乏经验的动作序列会导致零奖励的产生。很多 Web 任务都有这个问题,因为它们都有很大的动作空间(智能体可以点击任何地方,输入任何字符),并且需要正确的动作序列来完成任务。
强化学习中一个一个常见的对策是通过动作克隆预训练智能体让其模仿专家演示,以鼓励其在相似的状态下采取相似的动作。但是在一些有着多样且复杂的状态的环境中,如网站,演示只能够覆盖一小部分状态空间,而且学习到的策略很难泛化到其他状态(过拟合)。事实上,前人的工作已经发现通过动作克隆预训练的策略很难通过纯粹的强化学习提升。同时,简单的对抗过拟合的方法(使用更少的参数或者正则化)会减弱模型的灵活性,而这对于用户界面的复杂空间以及结构化推理是必要的。
文章贡献
本文提出了一个不同的利用演示的方法——通过演示限制智能体的探索,而不是训练智能体模仿它们。通过删除错误的探索方向,可以提升智能体探索奖励的能力。并且,因为演示并不直接展示给智能体,我们可以使用更加复杂的神经策略,而不需要担心过拟合的风险。
为了限制探索,我们提出了工作流的概念。例如,转发邮件的工作流是:点击邮件标题 点击转发按钮 在文本框内输入邮箱地址 点击发送按钮。
相较于真正的策略来说,工作流层次更高:它并不告诉智能体要点击哪一封邮件或者在哪个文本框内输入字符,但是它可以限制每一个时间步可以选择的动作。即,工作流是与环境无关的,它并不依赖于环境的状态是怎样的,它只是一系列可以盲目遵循的步骤。最终的策略当然不能与环境无关,但是在探索的过程中,环境无关性是一个很好的归纳偏差。
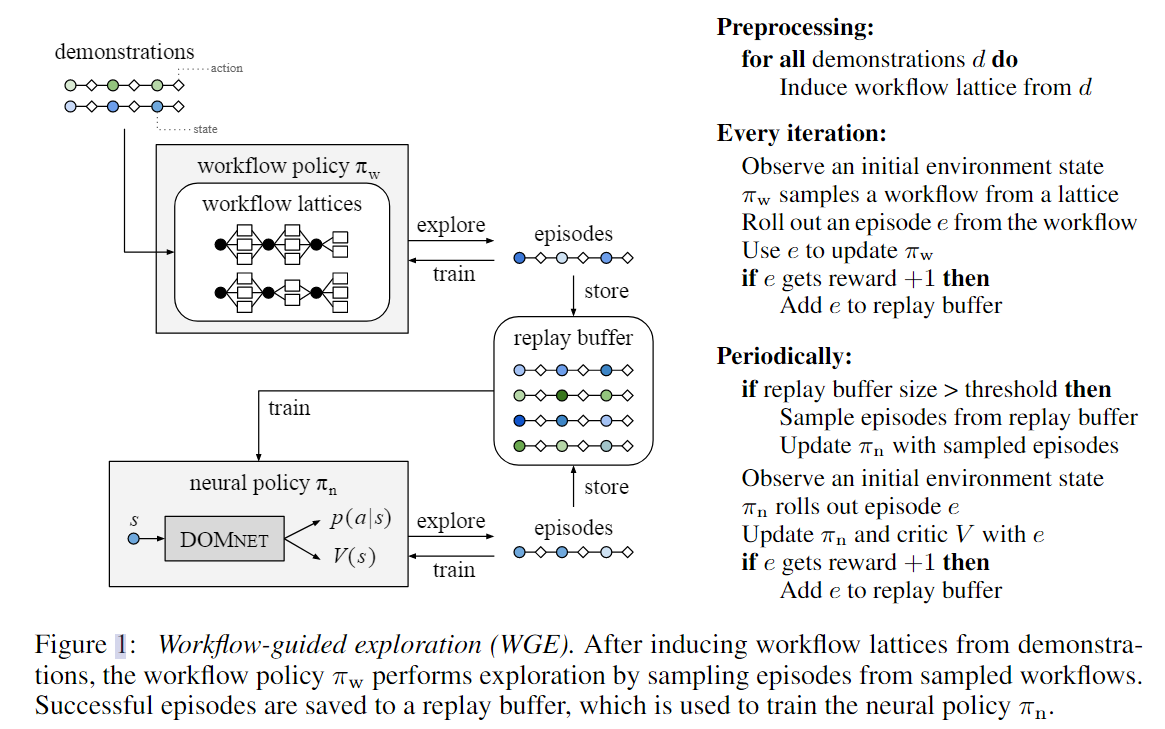
基于工作流的探索过程(workflow-guided exploration, WGE)工作方式如上图所示:
- 对于每一个演示,提取与演示中观察到的操作一致的工作流网格。
- 定义工作流探索策略 ,其探索过程为:先选择一个工作流,再采样匹配这个工作流的动作。这个策略在强化学习的过程中会逐渐学习到应该选择哪个工作流。
- 探索过程中发现的能够获得奖励的过程会被放入经验回放池,并且被用来训练一个更加强力的神经网络策略 。
Web 环境和传统的强化学习环境(如机器人或者游戏)一个主要区别在于:Web 环境的状态同时包括了结构化信息(如 HTML)和非结构化信息(如自然语言和图像)。因此本文同样提出了一个理想的神经网络策略 DOMNet ,专门设计用来在网站的树形结构的 HTML 表示上进行灵活的关系推理。
最后,在一系列的 Web 交互任务中测试了基于工作流的探索方法和 DOMNet ,包括 MiniWoB 环境,Alaska Airlines 的机票预订界面,以及我们自己建立的用于研究其他挑战(如噪声环境、自然语言的不同表述以及更长的时间窗口)的任务集。相较于 MiniWoB 在每个任务中使用了 10 分钟的演示(大约平均有 200 个演示),我们的方法仅仅使用 3~10 个演示,却有着更高的成功率,并且表现出了新的先进结果。
问题描述
本文的研究关注延迟奖励与稀疏奖励的情况。关于奖励,有以下两点假设:
- 智能体只在一次试验(episode)的最后一步获得奖励。
- 只有很小一部分的动作轨迹会收到正奖励(),其他的大部分情况统一为负奖励()。
在状态空间和动作空间都很大的情况下,延迟奖励与稀疏奖励使得智能体难以探索到有正奖励的试验,这降低了智能体学习的效率。
除了奖励之外,还假设智能体被设定了一个目标 ,这个目标可以是结构化的(如 {task: forward, from: Bob, to: Alice}),也可以是非结构化的(如“把 Bob 的邮件转发给 Alice”)。智能体观测到的状态 包括了目标 和网页的当前环境,表示为树形元素(DOM 树)。智能体可以选择的动作被限制为 Click(e) 或者 Type(e, t) ,其中 e 是 DOM 树上的叶子节点,t 是目标 中的一个字符串。如果智能体成功完成任务,奖励就为 ,否则为 。
解决方法
从演示中提取工作流
给定一个专家演示集合 ,定义工作流步 为一个函数,其输入为状态 ,输出为一个动作集合 ,包含了与 相似的动作。例如: Click(Tag("img")) 表示的集合 包括了所有对于有 img 标签的 DOM 元素的点击动作。工作流 就是工作流步的序列。
接下来定义工作流集合。对于演示 的每一个时间步,都可以定义一个集合 包括在时间 所有可能的工作流步 ,即集合 中的所有工作流步 都满足 。这样,所有的工作流集合一共可以创造 条工作流。如下图所示:
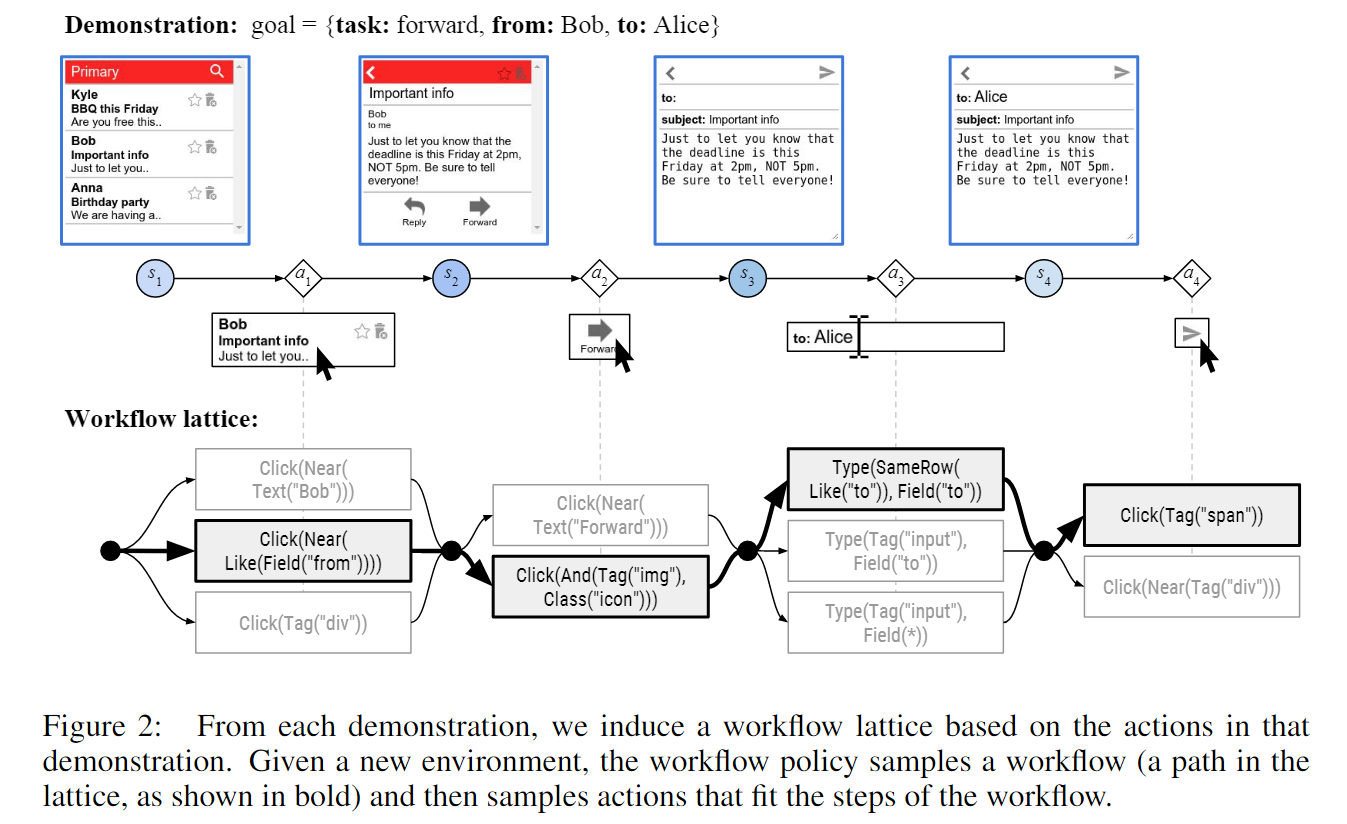
为了解决有些动作是不必要的情况下演示噪声的问题(如专家偶然点击了一下页面的空白处),引入了可以跳过一些时间步的步骤。同样地,对可以压缩成一个等价动作的动作(如依次输入两个字符等价于一次性输入两个字符)提供跳过步骤。这些跳过步骤使得引入的工作流长度不一定和演示长度相等。在之后的讨论中,为了简化符号,会忽略跳过步骤。
引入的工作流步也存在一些问题。如上图,工作流步 Click(Near(Text("Bob"))) 对于演示环境来说过于具体,但是 Click(Tag("div")) 又过于泛化,可能引入很多不相关的操作。因此接下来就需要讨论工作流策略 如何学习应当选择哪个工作流。
工作流探索策略
首先,探索策略考虑给定的目标 ,选择一个有着相似目标的演示 :
这里的 表示目标 和演示 的目标 的相似度。本文中,如果 和 有相同的关键字,就认为 ,其他情况值均为 。
接下来,在每个时间步 ,当环境的状态为 时,根据以下分布采样工作流步 :
这里的 是要学习的参数。最后,从集合 中采样动作:
这样,探索出的试验 的概率是:
这里 是状态转移概率,对于智能体来说是未知的。公式的整体思路是:要完成一个试验,首先需要根据目标 选择一个演示 ,然后在时刻 ,首先要能从 转移到 ,在 时刻,需要找到所有选择动作 的可能性(先选择工作流步,再从工作流步中选择动作 )。
值得注意的是: 是一个与环境状态 无关的函数,其决策只与选择的演示和当前时间 有关。这种环境无关性让模型 拥有更少的参数和更快的学习速度,并且能防止过拟合。虽然环境无关会让工作流策略不能真正完成任务,但是它可以快速学习到一些好的动作,这可以帮助之后的神经策略学习。
为了训练工作流策略,使用了 REINFORCE 算法的变体。具体地,用以下公式通过无偏估计来近似梯度:
其中 是时间步 的回报, 是用于减小方差的基线项。
从工作流策略中采样到的能够获得正奖励的试验会被储存到经验池中,用于训练神经策略 。
神经策略
神经策略同时通过同策略更新和异策略更新进行学习(训练数据从经验池中进行采样)。两种更新方式都采用同步版本的优势演员-评论家(A2C)算法。因为只有获得了 奖励的试验会进入到经验池,异策略更新就像是在最优轨迹上进行监督学习。此外,在同策略更新过程中发现的成功的试验也会被加入到经验池中。
本文提出了 DOMNet ,一个提取 DOM 树上空间结构和等级结构信息的神经网络。其结构如下图所示:
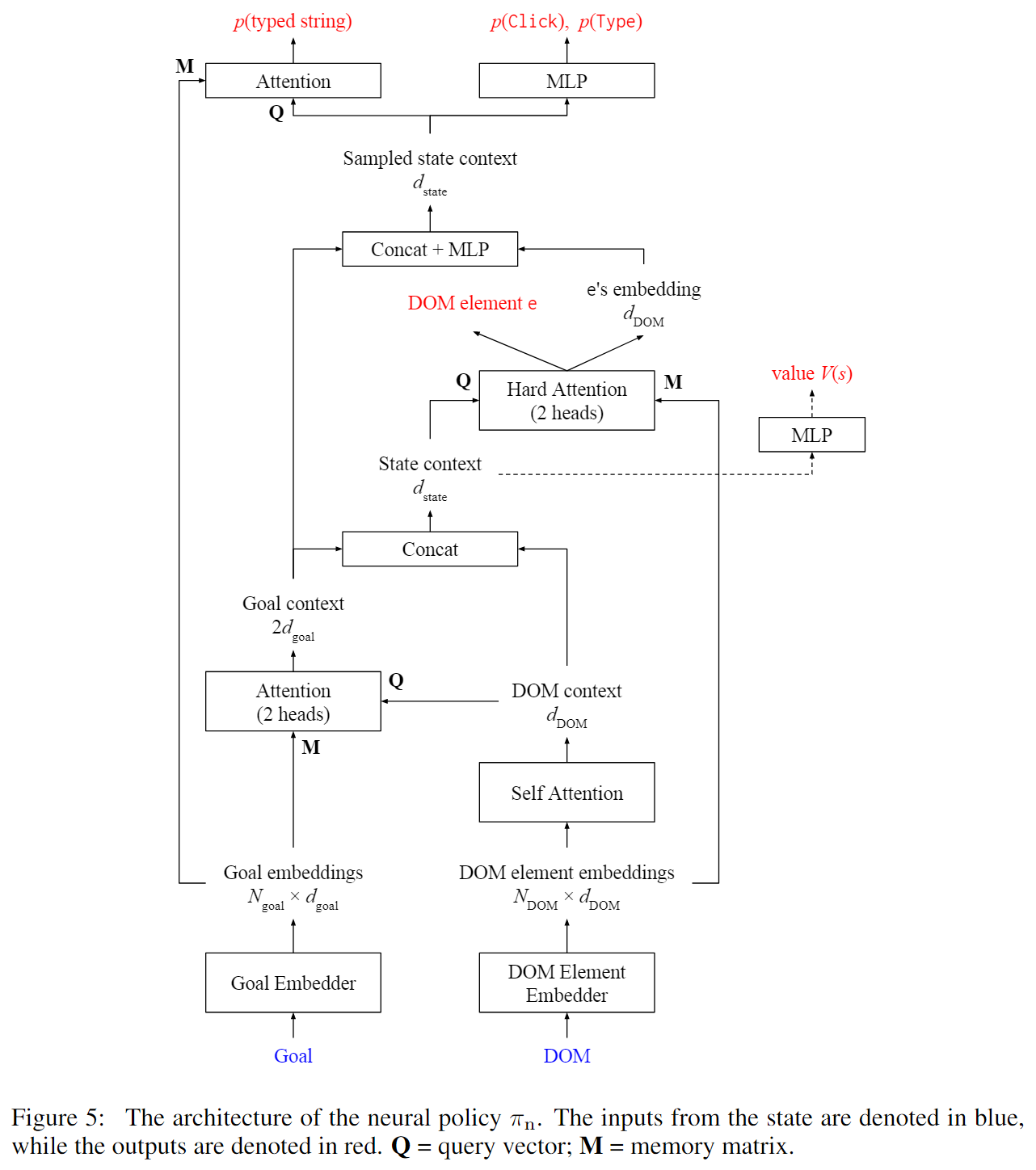
首先,网络对 DOM 元素和输入的目标进行嵌入操作。然后网络对嵌入向量进行一系列的 attention 操作以产生最终的动作分布 和价值函数 。
DOM embedder 的作用在于提取 DOM 元素之间的各种交互数据。具体地,”相关的“ DOM 元素之间(比如一个复选框和它对应的标签)应该互相传递信息。为了对 DOM 元素 进行嵌入操作,首先通过嵌入与连接其属性(标签、类、文本等)来计算基础嵌入 。接下来,为了提取 DOM 元素之间的关系,计算以下两种邻居嵌入:
- 定义和 相距 30 个像素以内的元素 为 的空间邻居。将空间邻居的基础嵌入求和,就得到 的空间邻居嵌入 。
- 如果元素 和元素 在 DOM 树上的最近公共祖先的深度至多为 ,那么就称 是 的深度 树上邻居。直观上看,更深的树上邻居会更加相关。对于每一个深度 ,对每个深度 树上邻居 的基础嵌入应用一个可学习的仿射变换 ,再进行最大池化操作以得到 。将 的嵌入串联起来,得到元素 的树上邻居嵌入 。
最后,定义目标匹配嵌入 为元素 的所有单词中,出现在目标里面的单词的嵌入之和。将上述四种嵌入串联起来,就得到了元素 的最终嵌入: 。
实验验证
任务设置
在三个交互式 Web 任务数据集上测试了本文所提出来的方法:
- MiniWoB:World of Bits 论文中的 MiniWoB 环境。
- MiniWoB++:自己构造的新数据集,包括了一些 MiniWoB 中没有涉及到的挑战,如随机环境以及自然语言描述的变化。
- Alaska:Alaska Airlines 的手机机票预定界面。
环境描述:每个任务都包括一个 像素的环境和一个用文本描述的目标。大多数任务在试验结束之后会返回一个单独的稀疏奖励 (成功)或 (失败)。为了任务之间的一致性,本次试验删除了所有的部分奖励,智能体通过 Selenium 库的 Web driver 界面访问环境。
公开的 MiniWoB 环境有 80 个任务。本次实验筛选出了 40 个只要求智能体执行本文定义了的动作的环境,即点击 DOM 元素和输入目标中的字符串。其他的任务都需要一些专业的推理,如计算角度,或者解决代数问题。对于每个任务,使用 Amazon Mechanical Turk 录制了 10 个演示。
测试指标:成功率:获得了 奖励的试验的比例。由于删除了所有的部分奖励,成功率与平均奖励是线性相关的。
对比方法
本次实验一共对比了三个方法:
- SHI17:World of Bits 论文中的方法,使用 10 分钟的演示(约 200 个演示)通过动作克隆进行预训练,再通过强化学习进行微调。该系统的状态表示为像素图像。
- DOMNet+BC+RL:本文提出的神经策略,DOMNet,但是像 SHI17 一样使用 10 个演示通过动作克隆进行预训练,再通过强化学习进行微调。再动作克隆的过程中,通过验证集的奖励情况提早停止训练。
- DOMNet+WGE:本文提出的神经策略,DOMNet,并且使用 10 个演示通过基于工作流的探索进行训练。
对于 DOMNet 相关的两个算法,成功率记录为在验证集上达到的最大成功率。
实验结果
实验结果如下图所示:
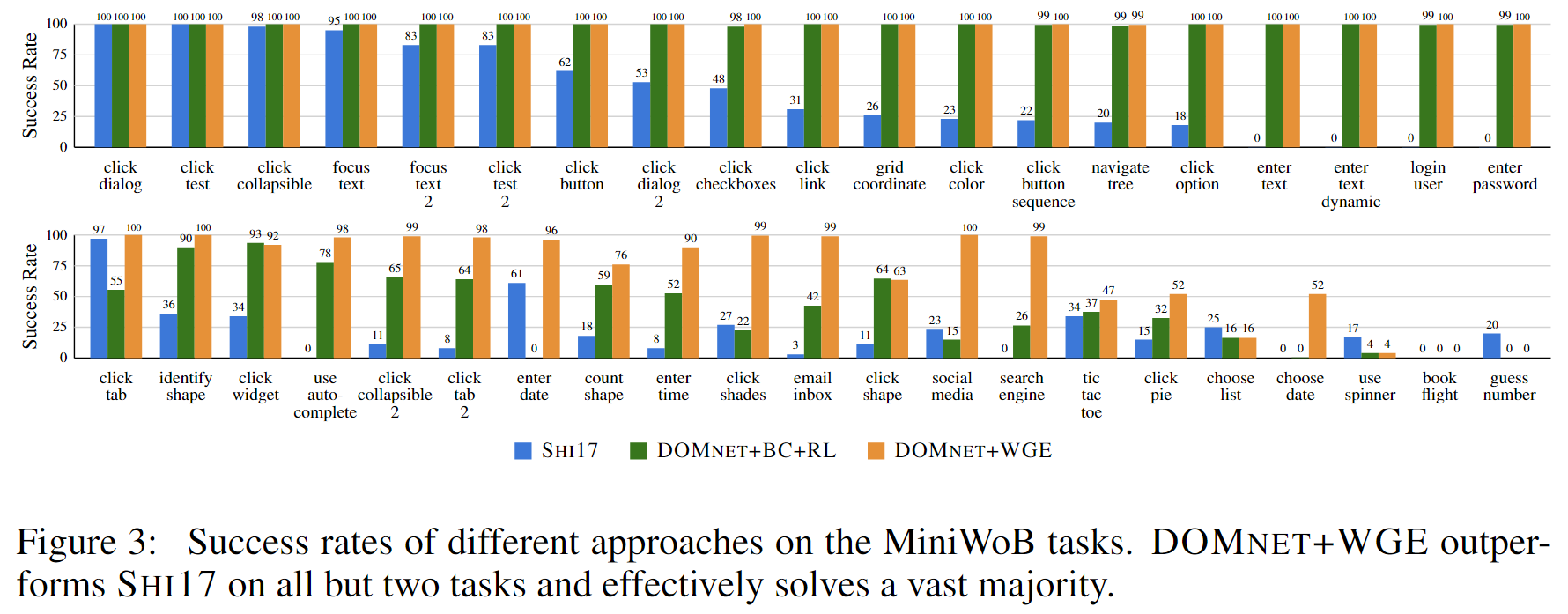
对比 SHI17 和 DOMNet+BC+RL 可以发现:在大多数任务上,DOMNet+BC+RL 提高了成功率。
对比 DOMNet+BC+RL 和 DOMNet+WGE 可以发现:基于工作流的探索让 DOMNet 在更难的任务上表现得更好。
具体分析
MiniWoB++ 环境
本文构建并发布了 MiniWoB++ 环境,包括用于研究额外的挑战的任务。如:更长的时间窗口(click-checkboxes-large),自然语言的“软”推理(click-checkboxes-soft),以及随机变化的布局(multiorderings, multi-layouts)。下表列出了任务的时间窗口(实现最长目标的完美策略所需要的步骤数),作为衡量任务复杂性的粗略标准。

实验结果表明:相较于 BC+RL 模型,WGE 模型在绝对成功率上提升了约 。分析模型的行为,可以发现有两种模式,BC+RL 模型经常失败,但是 WGE 可以减轻对应的问题。
- BC+RL 模型倾向于选择让环境过早停止的动作,如在检查所有必须填写的项目之前点击提交按钮。一个可能的原因是:这些动作在所有的演示中都出现了,但是那些不会导致环境停止动作(如点击不同的复选框)在不同的演示中是不同的。
- BC+RL 模型偶尔会陷入循环操作,如反复勾选/取消勾选同一个复选框。这种错误类型是对部分演示的过拟合导致的,而 WGE 就可以避免这个问题。
接下来,分析 WGE 学习到的工作流策略 。 自身过于简单,从而不能在测试时表现得很好,有以下几点原因:
- 工作流忽略了环境状态,因此不能对环境中的不同做出响应,如 multi-layouts 中的不同布局。
- 工作流限制了语言表达,因而缺少了指定某些动作的表达能力,如在 click-checkboxes-soft 中点击某个单词的同义词。
- 对于一个给定的目标,工作流策略缺乏选择正确工作流的能力。
尽管如此,工作流策略 的约束已足以让其在一些时候发现奖励,神经策略 就可以从这些试验中学习正确的行为。正因如此,神经策略可以获得很高的成功率,即使工作流策略表现很差。
自然语言输入
MiniWoB 任务提供的目标都是结构化的,本文也在自然语言描述的目标上测试了 WGE 算法。通过隔夜数据收集技术构建了训练集。在 email-inbox-nl 任务中,通过让注解员解释任务目标收集了自然语言模板(如将“"Forward Bob’s message to Alice”解释为“Email Alice the email I got from Bob”),然后提取字段(Email <TO> the email I got from <FROM>)。
在训练过程中,工作流策略 接收同时包括结构化目标和从随机模板生成的自然语言表述的状态,而神经策略 只接收自然语言表述。在测试时,神经策略在看不见的自然语言表述上进行评估。实验结果表明 WGE 模型可以学会理解自然语言目标。
值得注意的是:工作流策略需要结构化的输入只是因为我们对工作流步的语言限制是基于结构化输入的。语言限制也可以修改为直接使用自然语言表达,这会是未来的研究工作。
扩展到现实世界的任务
本文还在 Alaska 环境上进行了试验。在这个环境中,智能体必须根据给定的信息,完成航班的搜索。在本文中,将网页移植到 MiniWoB 框架中,屏幕更大,为 像素,用代理 JavaScript 函数替换了服务器后端,并将环境日期限制在 2017 年 3 月 1 日。
在此任务中,根据提交的表单中正确字段的分数给予部分奖励。尽管有部分奖励,奖励还是非常稀疏:有 200 多个 DOM 元素(MiniWoB 任务中只有 10~50 个),一个典型的试验需要至少 11 个动作,涉及到各种类型的部件,如自动填充和日期选择器。随机策略的智能体能够获得正奖励的概率小于 。
首先在 Alaska-Shi17 环境上进行了实验,这是原论文环境的一个镜像,环境中的目标总是指向往返航班(需要指定两个机场和两个日期)。在这个数据集上,本文的方法只使用了 1 个演示,就获得了 的平均奖励;而原论文的方法使用了 80 个演示,也只获得了 的奖励。
随后,在更加复杂的任务中进行了实验,现在智能体需要选择航班类型(一个复选框表示是否为单程航班),乘客人数(一个加减计数器),以及座位类型(隐藏在折叠菜单下)。我们在使用 10 个演示的情况下达到了 的平均奖励。这证明我们的方法能够处理真实世界中的长任务。
采样效率
将 DOMNet+WGE 和 DOMNet+BC+RL 在不同的演示数量上进行实验,实验结果如下图所示:
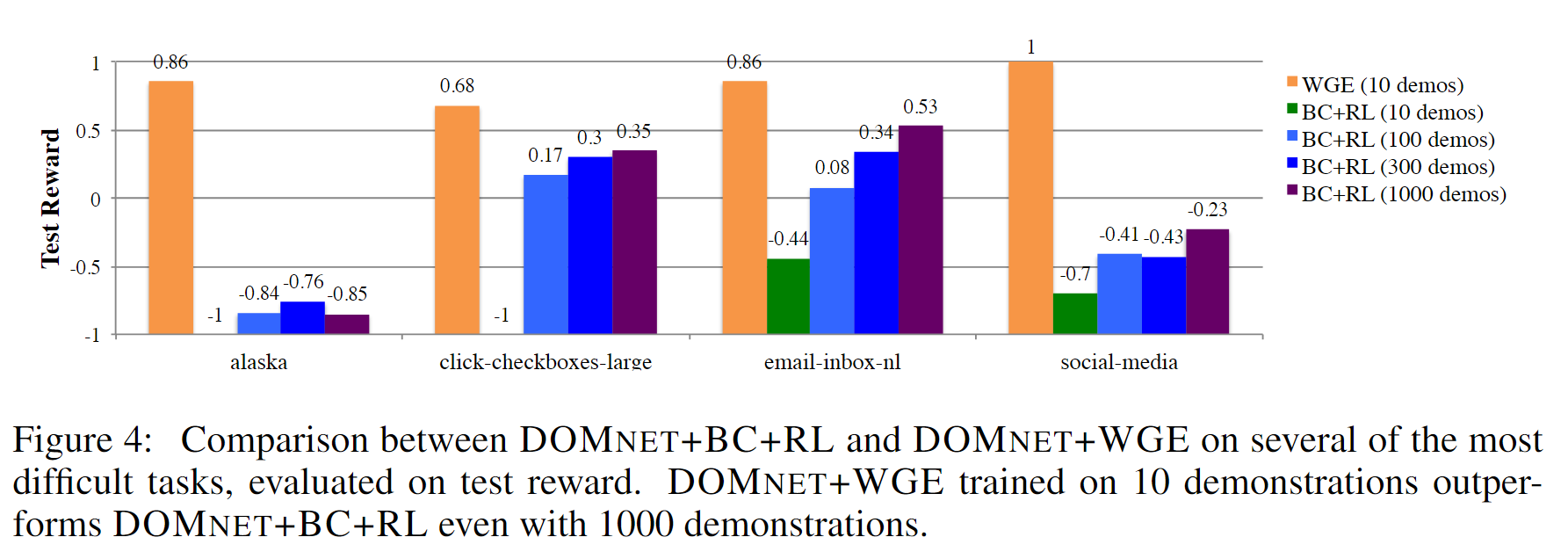
可以发现:通过增加演示的数量,BC+RL 方法的表现确实得到了提高,因为这会防止过拟合。但是,在每个任务上,只是用 10 个演示训练的 WGE 效果还是要好于用 1000 个演示训练的 BC+RL 。这说明:就演示数量而言,WGE 方法的采样效率相较于动作克隆方法提升了超过 100 倍。