[强化学习从入门到入土]强化学习基础
申明:本系列为《深度强化学习:基于 Python 的理论及实践》一书及相关论文的学习笔记。
从零开始的强化学习,那必然要先了解一些最基本的概念,为之后算法的学习打好基础。
引入
在日常生活中,我们经常会碰到一些顺序决策问题(任务),如下棋、驾驶等。在这些问题中,首先,我们会有明确的目标:赢下这一场棋,或者是安全到达目的地;其次,我们每采取一个动作,都需要接受外界的的反馈,如棋盘上局势的优劣,驾驶中到目的地的距离等;为了达到我们的目标,我们必须采取一系列动作,每一步动作都会改变外部世界(给予我们的反馈)。我们通过观察每一步动作之后外部世界的改变,来决定我们的下一步动作。
对于人类来说,上面所描述的场景可以在脑海中直观地完成。而当我们想要电脑也能够像人类一样,进行上述过程时,强化学习这个概念就自然而然地产生了。用人类来类比强化学习的过程,我们将人类看成是电脑,或者更专业一点,称作为“智能体”(Agent)。而棋盘的状态,或者我们到目的地的距离、路上的路况之类,被称作为“环境”(environment)。环境产生描述系统状态的信息,这些信息被称作为“状态”(state)。智能体观察状态,并利用观察到的信息选择“动作”(action)与环境进行交互。环境接受动作并转换到下一个状态,向智能体返回一个新的状态和一个对应的“奖励”(reward),这个奖励可以被用来指导智能体学习的方向。当 这样一个循环完成之后,我们就说一个”时间步“已经完成。循环往复,直到环境终止(如问题解决)。整个过程可由下图所示控制回路进行描述:
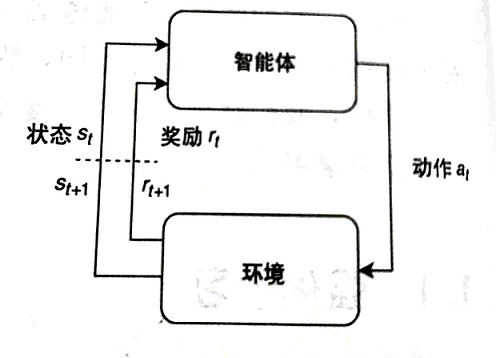
我们用三元组 来记录 时刻的状态,其表示在 时刻,环境的状态为 ,智能体所选择的动作为 ,获得的回报为 。假设环境从 时刻开始,到 时刻终止,这一整个过程被称作为一个事件,在这 个时刻中,我们也能通过 个三元组 来记录事件发生的过程,这被称作为轨迹。智能体往往需要通过大量的事件去学习一个较好的策略,来达到自己的目标(如最大化事件的奖励)。
马尔可夫决策过程
上述过程描述的其实就是一个马尔可夫决策过程(Markov decision process, 简称 MDP),不过为了让这个模型更加准确,我们还需要进行一些数学上的工作。
状态转换
根据之前的描述,环境每时每刻都处在某种状态之中,并且状态会因为智能体给出的动作进行改变。因此,对于环境会有一个状态空间 ,它表示了环境可能处于的所有状态;对于智能体,会有一个动作空间 ,它表示了智能体能够执行的所有动作。根据马尔可夫链的思想,状态之间的转换是按照一定的概率进行的,智能体的动作会影响状态转换的概率,可以利用如下公式表示:
这表示由 时刻向 时刻的状态转换与 时刻的状态和动作都有关,但是这样会使得建立的模型过于复杂,因此我们将状态转换函数表示为如下形式:
这样子,我们就让 时刻向 时刻的状态转换只与 时刻的状态和动作有关。尽管这个模型很简单,但实践证明,它非常的强大,许多过程都可以用这种形式表达,包括游戏、机器人控制和规划等。我们会在之后的实践中看到这一点。
奖励函数
有了智能体所行动的环境模型,接下来一步,就是如何指导智能体在环境中按照我们所期望的行为模式进行行动了。最直观的想法就是通过“奖励”进行引导,如果智能体做出了我们期望的行动,那么就给予它较多的奖励,如果它的行动与我们所期望的相差比较远,那么就给予它较少的奖励,甚至给予惩罚。当然这一切都由我们所定义的奖励函数有关,它的形式如下:
这表:因为智能体在 时刻进行了动作 ,使得环境由状态 转换到了状态 ,所以我们给予它 的奖励。
回报函数
最后,我们需要让智能体的目标与奖励相关。当然,在不同的训练过程中,目标与奖励的相关方式会有所不同,因此我们利用**“回报”**来定义它。
“回报”被定义为事件序列中所有时刻所获得奖励的加权和:
其中 是加权因子,其取值范围为 。这是一个重要的变量,它改变了后续奖励的估值方式。
-
越小,后续时刻智能体所获得的奖励的权重就越少,目标变得越“短视”。极端情况下,当 时,目标只考虑初始奖励 ,即: 。 -
越大,后续时刻智能体所获得的奖励的权重就越大,目标变得越“有远见”。当 时,每个时刻所获得奖励的权重是相等的,即: 。
目标函数
而智能体的目标,就被定义为诸多轨迹中,回报的期望值:
其中 表示智能体学习到的策略, 表示在策略 的指导下,智能体的行为形成了事件 。由于动作与环境具有随机性,智能体多次进行同一件事可能会产生不同的事件路径。正因如此,我们才需要对回报求期望来获得我们最终的目标。但实际上,最大化目标与最大化回报本质上是相同的。
最后再稍微讨论一下 对目标的影响:对于无限时间范围的问题,我们需要设置 防止目标变得无界;而对于有限时间范围的问题, 是一个重要的参数,根据加权因子的不同,一个问题可能会变得更加难或者更加容易解决。因此合理地设置加权因子的值也是一门值得探讨的学问。
MDP 控制循环
将强化学习定义为 MDP 和目标之后,我们可以将本文最开始那张图中的控制回路表示为下面代码中的控制循环:
1 | # 给定环境和智能体 |
在每个事件的开始,环境和智能体被重置(line3~4)。之后,环境和智能体开始进行交互。在每一个时间步中,智能体首先根据自己的策略,针对环境的状态产生一个动作(line6),接着环境根据智能体的动作产生下一个状态,并且给予智能体相应的奖励(line7),智能体根据自身的行动、环境的状态和获得的奖励进行学习(line8),然后进入下一个时间步,直到达到最大时间步 或者环境终止(事情结束)。
这样一个算法是所有强化学习问题中的通用算法,因为它定义了智能体和环境之间的一致接口。我们之后,将以这个接口为基础,实现各种各样的强化学习算法。
强化学习中的学习函数
到此为止,我们还有最后一个问题:强化学习,学习的是什么呢?
根据之前的分析,我们发现:智能体需要学习一个被称作为“策略”的动作生成函数。然而,环境的其他属性也可能对智能体有用。特别地,在强化学习中,有三个主要函数:
- 策略 ,将状态映射到动作: 。
- 估计期望回报 的值函数 或 。
- 环境模型 。
注:为了使符号简洁,通常将一对连续的元组 、 写成 、 ,其中
'代表下一个时间步。
策略函数
策略 是智能体在环境中产生动作以使目标最大化的规则。给定强化学习控制循环,智能体必需在观察到状态 后的每个时间步生成动作,使得循环继续进行。
策略可以是随机的,即智能体可以为同一状态输出不同的动作。我们可以把策略写成 来表示给定状态 生成动作 的概率,那么从策略中取样的动作就可以写成: 。
值函数
值函数提供关于目标的信息,它有助于智能体了解在期望状态下,后续回报和动作的关联程度。值函数有两种形式: 和 。
其中 函数的形式如下:
它被用来评价一个状态的好坏:假设智能体继续按照当前策略 执行动作, 函数评估处于状态 的期望回报。它评价的是从当前状态 到结束时的总回报,这是一个前瞻性的评估,因为所有在状态 之前的回报都被忽略了。
函数的形式如下:
和 函数相比, 函数只是多了一个对于 时刻时时间步的限定,因此它被用来评估一个状态、动作对的效果。假设智能体继续按照当前策略 执行动作, 函数评估在状态 下采取动作 的预期回报。同上,这个评估也是前瞻性的。
环境模型
环境状态的转换函数 提供有关环境的信息。如果一个智能体学习了这个函数,它就能够预测在当前状态 中执行动作 之后环境将转换到的下一个状态 。通过运用学习到的转换函数,智能体可以“想象”其动作的后果,而不必接触实际环境。然后它们可以利用这些信息来计划更好的动作。
参考文献:
- Luara Graesser, Wah Loon Keng《深度强化学习:基于 Python 的理论及实践》