[论文解读]learning to navigate the web
论文地址:learning to navigate the web 。
摘要
在有着巨大的状态空间和动作空间,以及稀疏奖励的环境中进行学习,会阻碍强化学习智能体通过试错的学习过程。例如,在网页上遵循自然语言命令执行操作(如预定机票),会创造一个输入词汇量和单个页面上可操作元素数量非常庞大的强化学习环境。即使最近的研究通过人类演示引导探索,在相对简单的环境中提升了成功率,在那些可能有成千上万条可能的指令的环境中,这些方法还是会失败。我们尝试从一个不同的角度解决前面提到的问题,并提出了一个可以生成无限用于智能体学习的经验的强化学习引导方法。我们不让智能体从含有大量词汇的复杂指令中进行学习,而是将这些指令分解成多个子指令,并且规划了一个“课程表”,使得智能体在一个递增的相对容易的子指令集中进行学习。除此之外,当专家演示不可用时,我们提出了一个理想的元学习框架以生成新的指令跟随任务,并且更有效地训练智能体。我们使用一种新的 QWeb 神经网络架构在这些较小的合成指令上近似 Q 值函数,并基于此训练 DQN 深度强化学习智能体。我们在 WoB 环境上测试我们智能体泛化到新的指令的能力。并且在超过 100 个元素,支持超过 1400 万种可能的命令的表单上进行测试。QWeb 智能体在一些困难的环境中,不使用任何人类演示,但是表现超过了 baseline,达到了 的准确率。
研究背景
在一个经典的 web 环境中,一个智能体需要仔细浏览大量的网络元素,以遵循从大量词汇中构建的高度变化的指令。例如对于指令“Book a flight from WTK to LON on 21-Oct-2016”,智能体可以以任何顺序填写前三个字段;选择的选项很多,但是在所有可能的机场/日期组合中,只有一个是正确的;只有在填写完所有的三个字段之后,才能提交表单;在这之后,网络环境/网页会发生变化,才可以选择航班。因此这个任务是十分困难的。在这样的任务中,通过试错去达到最终的目标是繁琐的,并且稀疏奖励会导致大多数 episode 根本不会产生任何信号。并且当智能体从大量指令中学习时,由于不一定能访问到每个选项,这个问题会更加严重。
对于这个问题,一个常见的解决方法是:通过从人类演示中学习,以及使用预先训练好的词嵌入来引导探索走向更有价值的状态。但是前人的工作对于每个环境使用了单独的演示,随着环境的复杂性增加,这些方法无法产生任何成功的 episode 。并且,在有着巨大动作和状态空间的环境中,收集人类演示这一行为无法扩展,因为对于每个环境,需要大量的人类演示用于训练。
文章贡献
本文提出了两种网页导航中大型状态和动作空间,且奖励稀疏的强化学习方法。当有专家演示或者一种指令遵循策略(ORACLE)时,我们提出了 curriculum-DQN,这是一个课程学习方法,引导探索从一些更简单的命令遵循任务开始,在大量的训练中逐渐增加难度。curriculum-DQN 将一个命令分解成多个子命令,并且将这些子指令集中的更简单的任务分配给导航智能体去做。一个专家指令遵顼策略(ORACLE)能够让智能体更加靠近其目标。
当专家演示和 ORACLE 策略不可用的时候,我们提出了一个新的元学习框架,利用无指令的任意网络导航策略,训练一个专家指令遵循演示的生成式模型。这其中的关键点在于:我们可以将一个任意的导航策略(如随机策略)视为某些隐藏指令的专家指令遵循策略。如果我们能够复原这些隐藏指令,那么我们就可以自动生成新的专家演示,并且用他们来提升导航智能体的训练。直观上来说,从策略中生成指令比遵循指令更加容易,因为导航智能体不需要和动态网页交互并且采取复杂的行动。因此,我们开发了一个指导智能体 meta-trainer ,通过生成新的专家演示来训练导航智能体。
除了两种训练方法,本文还提出了两个新的神经网络结构 QWeb 和 INET 用于嵌入网页导航中的 Q 值函数,融合了自注意力,LSTM 和浅编码。QWeb 是用于指令遵循策略的 Q 值函数,可以和 curriculum-DQN 或指导智能体。而 INET 是指导智能体的 Q 值函数。我们在 Miniwob 和 Miniwob++ 数据集上测试了我们方法的性能,发现这两种方法都改进了一个强基线,并且超过了先前最先进的技术。
同时,本文所提出的方法,基于有注意力机制的 DQN 的自动化课程生成可能会被大型任务计划社区内的工作者所感兴趣。因为它们可以帮助解决大型离散状态空间和动作空间马尔可夫决策过程下的目标导向任务。
问题描述
给定命令 ,其中 是字段 的列表,每个字段表示为一个键值对 (如 {from: ”San Francisco”, to: ”LA”, date: ”12/04/2018”})。在每个时间步,环境的状态 包括指令 ,和网页的 DOM 树表示 。每个 DOM 元素被表示为命名属性(如 tag, value, name, text, id, class 等)的列表。环境的奖励是通过比较一个 episode 的最终状态 和最终目标状态 计算得到的。动作空间被限制为 Click(e) 和 Type(e, y) ,其中 是 DOM 树上的一个叶子 DOM 元素, 是指令里面一个字段的值。这两个复合操作主要通过 DOM 元素 来识别,如文本框是通过序列进行键入,而日期选择器是通过点击进行选择。这样的性质启发我们将复合动作表示为原子动作的层次结构,如图 2 所示:
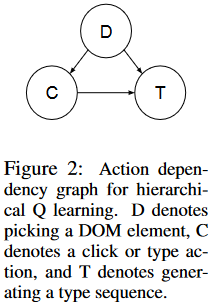
在这个框架下,考虑节点之间的依赖关系,分别对图中的节点进行建模,再组合起来定义组合 Q 值函数:
其中 是组合动作, 表示选择一个 DOM 元素, 表示在选定的 DOM 元素上的点击或输入操作, 表示在选定的 DOM 元素上输入命令中的一个序列。在执行策略时(在探索的过程中或者测试的过程中),智能体首先选择具有最高的 的 DOM 元素;然后基于 在选择的 DOM 元素上选择输入或点击操作;对于输入操作,智能体利用 从命令中选择一个值。
解决方法
用于网页导航的引导型 Q 学习
在本节中,首先介绍我们的深度 Q 网络,即 QWeb ,用于生成每个给定的状态 和每个原子操作 的 Q 值。接下来将解释我们如和使用 DOM 和命令的浅编码层扩展这个网络以解决学习一个巨大的输入词典的问题。最后,我们深入研究了我们的奖励增强和课程学习方法以解决前面提到的问题。
用于网页导航的深度 Q 网络(QWeb)
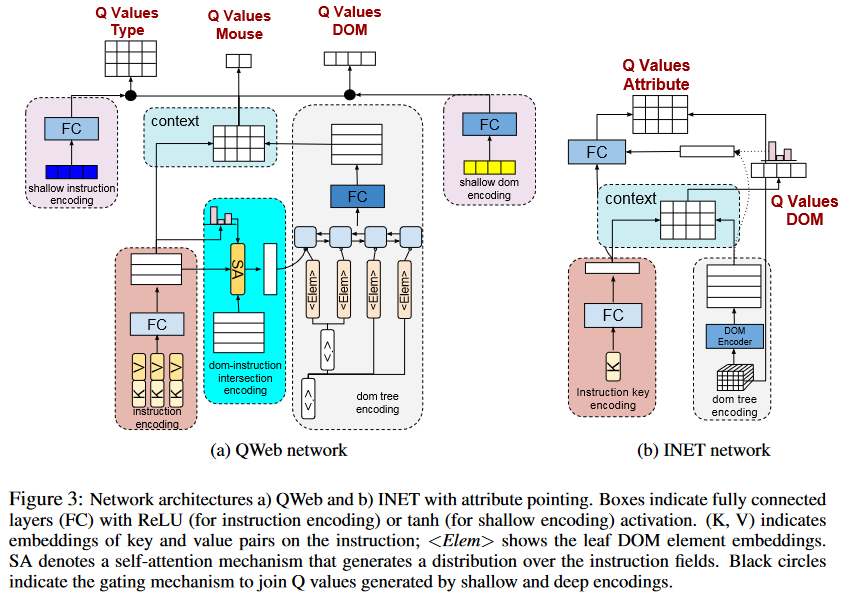
如图 3a 所示,QWeb 由三个不同的层组成,这三个不同的层以层次结构的形式连接,每个层对给定状态的不同部分进行编码操作:
- 编码用户命令。
- 编码 DOM 元素属性和用户命令中重合的文字部分。
- 编码 DOM 树。
给定一个命令 ,QWeb 首先通过学习每个 和 的嵌入,将每个字段 编码成一个固定长度的向量。DOM 元素属性和用户命令中重合的文字序列也被编码成一个单独的向量,以在相似上下文的情景下描述每个元素的情况。最后 DOM 树的编码是通过线性化树形结构之后,在 DOM 元素序列上应用一个双向 LSTM 网络(biLSTM)实现。LSTM 网络的输出和命令字段的编码会被用来生成每个原子动作的 Q 值。
用户命令编码 我们将一个命令表示为一个向量的列表,其中每个向量对应一个不同的命令字段。一个字段的编码过程为:首先编码对应的键和值,然后将组合起来的编码通过一个有着 ReLU 激活函数的全连接层(FC)进行转换,得到最终的编码。假设 分别表示第 个字段的键和值的第 个单词的嵌入表示。那么键和值的嵌入表示就是其单词嵌入的平均值,如 是一个键的嵌入表示。一个字段的嵌入通过公式 计算,其中 表示向量的拼接。
DOM-指令交叉编码 对于命令中的每个字段和一个 DOM 元素的每个属性,生成一个重复单词的序列。通过并行编码这些序列,我们能够生成命令导向的 DOM 元素编码。我们对每个序列和每个属性的词嵌入取平均,以计算在每个命令字段的条件下 DOM 元素的嵌入。我们使用自注意力机制计算指令字段上的概率分布,并将这个命令导向的嵌入降维成一个单独的 DOM 元素编码。假设 表示在字段 的条件下 DOM 元素的嵌入表示,其中 是第 个 DOM 元素。 的条件嵌入是所有这些嵌入的加权平均,即 ,其中自注意力概率的计算方式为: ,其中 是可训练参数。
DOM 树编码 首先将属性中的每个词嵌入取平均得到属性的嵌入表示。每个 DOM 元素的编码就是其属性嵌入的平均值。给定条件 DOM 元素编码,我们将它们和 DOM 元素嵌入连接起来以为每个 DOM 元素生成一个单独的向量。接下来在 DOM 元素嵌入列表之上应用一个双向 LSTM 网络(biLSTM)以对 DOM 树进行编码。biLSTM 的每一个输出向量之后会通过一个带有 tanh 激活函数的全连接层进行转换,以生成最终的 DOM 元素表示。
生成 Q 值 给定指令中每个字段的编码和 DOM 树上每个 DOM 元素的编码,我们计算每个字段和每个 DOM 元素之间的两两相似性,得到一个上下文矩阵 。 的行和列分别表示当前状态下每个字段和每个 DOM 元素的后验值。通过应用一个全连接层,并且对 的行求和,可以为每一个 DOM 元素生成 Q 值 。我们使用 的行作为将指令的字段输入一个 DOM 元素的 值,即 。最后,点击或输入动作的 Q 值是通过将 的行应用另一个全连接层转换为 维向量计算得到,即 。组合动作 的最终 Q 值就是这些 Q 值之和: 。
结合浅编码 在奖励稀疏且输入词汇量庞大的情况下,仅仅使用词嵌入很难学习到良好的语义相似性。我们使用命令和 DOM 树的浅编码来增强我们的深度 Q 网络,以缓解这个问题。首先通过计算每个命令字段和每个 DOM 元素属性之间的基于词的相似性(如 Jaccard 相似性,子集二进制指示器或者超集二进制指示器)生成联合浅编码矩阵。我们还将每个 DOM 元素兄弟节点的浅编码附加在一起,以明确地结合 DOM 层次结构。我们分别对浅编码矩阵的列和行求和,以生成 DOM 元素和命令字段的浅层输入向量。这些向量通过一个具有 tanh 激活函数的全连接层进行变换,并且通过一个可训练的参数进行缩放,以生成 DOM 元素和命令字段的浅层 Q 值。通过在深度 Q 值和浅层 Q 值之间应用门控机制,可以按照如下方式计算最终的 Q 值:
其中 和 是可训练参数。
奖励增强
我们使用基于潜力的奖励来增强环境中的奖励函数。因为环境奖励是通过评估最终状态是否完全等价于目标状态来计算的,我们定义潜力函数 计算给定状态 和目标状态 之间匹配的 DOM 元素的数量,并通过目标状态的 DOM 元素的数量进行归一化。基于潜力的奖励就是根据下一个状态和当前状态的潜力差异进行计算的:
课程学习
我们通过将一个命令分解成多个子命令,并且为智能体分配一些更简单的任务,即仅解决子命令的一个子集,来进行课程学习。我们使用两种不同的课程学习策略来训练 QWeb :热身策略和子目标模拟策略。

热身策略 如算法 1 中所示:为了在一个 episode 中进行热身,我们将智能体放置于距离目标状态更近的状态中,这样智能体就只需要学习遵循一小部分子命令就能够成功完成这个 episode 。我们以一个概率 独立地访问每个 DOM 元素,并通过 ORACLE 策略来对选择的元素进行正确的操作。在热身过程中,QWeb 的环境被初始化为最终状态,并且原始目标保持不变。并且在训练的开始, 值最开始设置为一个较大的值(如 ),并且在预定的部署内逐渐减少为 。超过这个限制之后,环境的初始状态将恢复为完整指令的普通 DOM 树原始状态。
目标模拟 为了为智能体模拟更加简单但是相关的子目标,我们将一个 episode 限制为只使用环境中的一部分元素,智能体只需要对应的子命令就可以成功完成这个 episode 。我们随机选择一个大小为 的元素子集,并且应用 ORACLE 策略进行正确的动作,以生成一个子目标。在目标模拟过程中,QWeb 环境的目标将被指定为这个过程的最终状态,并且环境的初始状态将保持不变。如果能够成功达到子目标,那么 QWeb 就会得到一个正奖励。在训练的最开始, 值被设定为 ,随着训练轮次的增加, 值逐渐增加到 DOM 树上最大的元素数量。超过限制之后,和热身策略一样,环境将会恢复为原来的环境状态。
用于训练 QWeb 的元学习
为了解决人类演示或者 ORACLE 策略不可用时可能产生的问题,我们将课程学习和奖励增强结合到一个更加通用的统一框架下,并且提出了一种新的元学习训练方法。该方法分为两个阶段:
- 首先通过 DQN 智能体 instructor 学习生成新的命令。instructor 学习如何恢复非专家策略(如基于规则的策略,或者随机策略)所遵循的命令。
- 一旦 instructor 训练完成,我们将对它进行调整,使其用于为基于简单的,非专家的,基于规则的策略的 QWeb 智能体提供演示。
总体训练过程如算法 3 所示:

从目标状态学习命令
命令生成环境 我们对每个环境中预定义的可能的键集合进行无重复采样,以采样到的目标和单个键 来定义一种命令状态。命令动作是组合动作:在网页导航环境中选择一个 DOM 元素()并生成一个于当前的键 对应的值()。在每个动作之后,如果键的对应生成值是正确的,智能体回得到一个正奖励 ,否则收到一个负奖励 。为了训练 instructor ,我们采用和课程学习中同样的采样过程,如算法 2 所示(只是状态、动作和奖励的设置有所不同):

一个命令生成的例子:在机票预定环境中,可能的键是 。假设当前的键是 ,并且智能体选择了出发这一 DOM 元素。那么可以用出发元素的一个属性作为生成的值,如
text: "LA"。
用于指令生成的深度 Q 网络(INET) 如图 3b 所示,为了学习命令生成环境的 Q 值函数,我们设计了深度 Q 网络 INET 。借用 QWeb 中的 DOM 树编码器,INET 使用 biLSTM 编码器为 DOM 树上的每个 DOM 元素生成一个向量表示。环境状态中的键的编码和 QWeb 中命令的编码类似,编码层只有唯一的输入,就是要编码的键。选择 DOM 元素的 Q 值是通过学习键和 DOM 元素之间的相似性 计算得出的,其中 表示 instructor 智能体的 Q 值。接下来,利用与键和 DOM 元素一样的相似性,生成 DOM 元素的概率分布,并且将编码降维成一个单独的 DOM 树编码。对于每个可能的属性,通过将上下文向量(由 DOM 树编码和键编码连接而成)转换为可能的 DOM 属性集的分数,生成 Q 值 。最后,将两个 Q 值结合起来,得到最终的 Q 值: 。
QWeb 的元学习(Meta-QWeb)
我们设计了一个简单的基于规则的随机策略(RRND),迭代地访问当前状态中的每个 DOM 元素并采取行动。如果动作是 Click(e) ,智能体就会点击这个元素,过程继续。如果 DOM 元素是一组元素中的一部分,其值是由组内其他元素的状态决定的(如单选按钮),那么 RRND 就会随机点击一个 DOM 元素,并且忽略其他的元素。然而,如果动作是 Type(e, t) ,输入的序列是从给定的知识源(KS)中随机选择的。当所有 DOM 元素都被访问,并且最终的 DOM 树 生成完毕之后,RRND 就会停止迭代。
输入从知识源中随机选择的例子:考虑航班预定环境,假设访问的元素是一个文本框,那么 RRND 会从一个可行的机场列表中随机选择一个机场,并将其输入到文本框中。
使用经过预训练的 INET 模型,我们从 上生成命令 ,并且利用 对设置网页导航环境。当 QWeb 采取行动,并从网页导航环境中观察到了一个新的状态后,新的状态被发送给元训练器以获得元奖励 。将 与环境奖励相加,就能得到最终的奖励: 。
即使我们使用一个简单的基于规则的策略来收集 episode ,根据环境的性质,也可以设计出不同的而类型来收集最终的状态。同时注意到,生成的目标状态 不一定需要是一个合法的状态。即使最终的目标状态不合法,MetaQWeb 依然可以通过利用不完整的 episode 和网页导航环境分配的命令目标对来训练 QWeb 。利用 MetaQWeb 来提供不同信号的可能性非常多,例如生成受监督的 episode ,进行行为克隆,为元训练器生成的 episode 规划课程,将 MetaQWeb 用作离线学习的行为策略等。在本文中,我们尝试使用基于潜力的稠密奖励 ,并将其他的情况留作未来的工作。
实验验证
我们在 Miniwob 和 Miniwob++ 中的大量环境中测试了我们的方法。我们使用一系列的需要点击和输入的任务组合为 QWeb 设置基准,其中也包括了一个困难的环境 social-media-all ,在这个环境中,先前的方法都没能产生任何成功的 episode 。
随后,我们在一个更困难的环境 book-flight-form (与原始的机票预订环境一致,仅仅使用原始网页表单,时间限制在一个月内)上进行了广泛的实验,这个环境需要智能体学习大量的状态和动作。每个任务都包括结构化的命令(同时也以自然语言表示)和一个用 DOM 树表示的 像素的环境。在 book-flight-form 环境下,我们将 DOM 元素的数量限制为 100 个,字段的数量为 3 个。因此,可能的动作数可以达到 300,状态中的变量数可以达到 600 。然而,这些数字仅仅是一个草图,并不能反应真实的 DOM 元素和命令字段。当有 700 多个机场时,这些数字会极大地增加,并且生成更大的空间。在 social-media-all 环境中,命令和 DOM 元素中有超过 7000 个不同的可能的值,任务长度为 12,这两个方面均显著高于其他环境。
奖励 所有的环境在 episode 结束之后会返回一个稀疏奖励,如果成功则为 ,失败则为 。我们还使用一个小小的步骤惩罚 ()来鼓励 QWeb 京可能使用较少的动作来完成任务。
测试指标 我们使用成功率作为指标,即有着 奖励的成功 episode 的比例。对于命令生成任务,如果命令中的所有值都成功生成,那么成功率就是 。
基线方法 将 QWeb 和之前的两个最先进方法进行对比。首先,SHI17 对每个环境使用大约 200 个演示,先通过动作克隆进行预训练,再通过强化学习进行微调。其次,LIU18 使用交替训练方法,迭代地训练程序策略和神经策略。程序策略被训练来从人类演示中生成高层次的工作流。神经策略利用演员-评论家网络,通过探索程序策略发现的工作流进行训练。
MiniWob 环境下的表现
我们根据状态空间、动作空间和输入词汇表的大小,再一组简单和困难的 Miniwob 环境中测试了 QWeb 的性能。实验结果如图 4 所示:
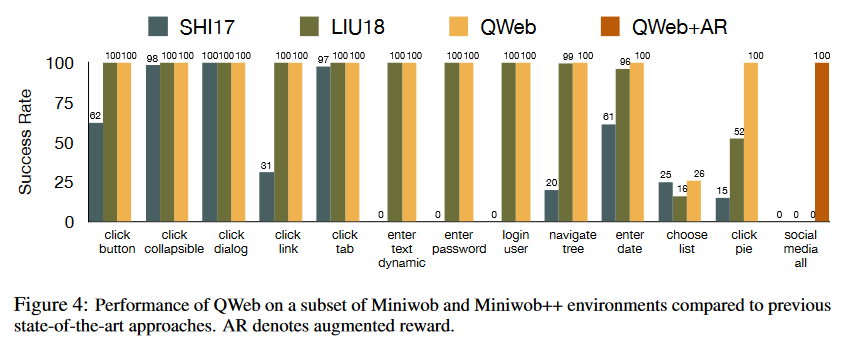
在简单的 MiniWob 环境(图 4 的前 11 个环境)中,我们展示了 QWeb 在没有任何浅编码,奖励增强,以及课程学习的情况下的性能。观察发现:QWeb 的性能在每个简单环境中都能和之前最先进的技术相媲美,这为我们后续对更困难的环境的研究提供了一个很强的基线方法。我们还可以确认:相较于对 DOM 层次结构进行编码提取特征,通过 biLSTM 编码器提取特征更加有效,因为 biLSTM 在每个环境上都能够一直得到具有竞争力的结果。
利用浅编码和奖励增强,我们还在更加困难的环境(click-pie 和 social-media-all)中测试了 QWeb 的性能。在 click-pie 环境中,episode 的长度很短(),但是智能体需要学习一个相对来说较大的词汇表(包括英语里的所有字母和数字)以正确推导命令和 DOM 元素之间的语义相似性。QWeb 在 social-media-all 环境上表现不佳的原因是该环境的词汇表大小超过 7000,并且任务长度为 12 。相较于其他环境来说,这些都明显变大了。另外一个原因是 QWeb 不能通过关注一个单独的节点来学习正确的动作,它需要将 DOM 树中节点的兄弟节点结合起来才能生成正确的动作。在所有这些环境中 QWeb+SE (shallow encoding,浅编码)成功完成了任务,并且在不使用任何人类演示的情况下,表现超过了之前所有的方法。我们的实证结果表明:在 social-media-all 环境中,同时使用浅编码和奖励增强技术是至关重要的,如果没有这些改进,我们不能纯粹通过试错训练出一个成功的智能体。如果没有奖励增强,QWeb 会过拟合,并且很快收敛到一个坏的最小值;在大多数情况下,策略会收敛为尽早终止 episode 以获得最小的步骤惩罚。
我们还在一些简单(loginuser, click-dialog, enter-password)和复杂(click-pie)的环境中分析了为了达到最好的效果,需要的训练步数,以研究从演示中学习的采样效率问题。我们发现使用演示可以加快学习的速度,LIU18 平均需要不到 1000 步,而 QWeb 需要多于 3000 步(对于 login-user 环境需要 96k 步)。但是在更加困难的 click-pi 环境中,效果会下降,LIU18 训练 13k 步之后达到了 的成功率,QWeb 在训练 31k 步之后达到了同样的成功率,并且在 175k 步之后达到了 的成功率。
机票预订环境下的表现
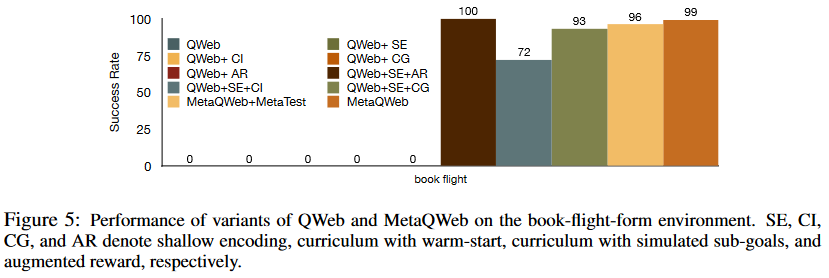
在图 5 中,我们展示了我们的每个改进在 book-flight-form 环境下的效果。如果不使用任何改进,或者只使用一种改进,QWeb 无法生成任何成功的 episode。主要原因是:(1)如果没有浅编码,即使在有着稠密奖励的情况下,QWeb 依旧无法学习到一个好的语义匹配;(2)如果只有浅编码,那么大部分的 episode 产生的奖励为 ,这阻止了 QWeb 学习。在分析第二种情况时,我们发现随着训练的进行,QWeb 会在第一个时间步就点击提交按钮,以获得最少的负奖励。当我们移除奖励乘法或者不给不成功的 episode 任何奖励时,QWeb 会收敛到以下两种情形之一:(1)在第一个时间步点击提交按钮;(2)生成一个随机的动作序列,直到达到步数限制,没有奖励的情况。当使用浅编码时,这两种课程方法都有巨大的改进,达到了 以上的成功率。当可以使用基于潜力的稠密奖励轻松地进行奖励增强时,我们获得了最大的收益,并完全完成了任务。
在测试 MetaQWeb 的性能之前,我们首先测试了 INET 在生成成功指令方面的性能,以研究 MetaWeb 引入的噪声对 QWeb 训练的影响。我们发现,INET 在完整生成命令的任务上达到了 的成功率,主要的错误原因是 DOM 元素预测错误()。除此之外,大多数错误出现在日期字段(),其中的值大多数从不正确的 DOM 元素中复制而来。
在利用元学习训练 QWeb 之后,我们在两种不同的情况下测试了其性能:(1)使用 MetaQWeb 生成的命令和目标对对 QWeb 进行元测试,以分析 QWeb 对噪声命令的鲁棒性;(2)我们使用原始环境进行测试。图 5 表明:在两种情况下,MetaQWeb 都产生了很强的结果,非常接近于完成任务。当我们分析使用元测试时出现的错误时,我们发现 的错误来自于不正确的命令生成,其中又有 的错误来自于错误的日期字段。当我们使用原始环境进行测试时,QWeb 的表现达到了 的成功率,这展示了元学习框架对于训练一个成功的 QWeb 智能体的有效性。
QWeb+SE+AR 和 MetaQWeb 之间效果差异可以归因于这些模型学习的生成经验的不同。在训练 QWeb+SE+AR 时,我们使用环境在最开始设置的,原始且干净的命令。而 MetaQWeb 是通过 instructor 生成的命令进行训练的。这些命令有的时候是错误的(错误率约为 )并且可能不能准确反应目标。这些噪声经验在一定程度上对 MetaQWeb 的性能造成了损害,导致了 的性能下降。
[论文解读]Adversarial Environment Generation for Learning to Navigate the Web
论文地址:Adversarial Environment Generation for Learning to Navigate the Web 。 摘要 学习如何自动在网页中进行导航是一个困难...
[论文解读]Mapping natural language commands to web elements
论文地址:Mapping natural language commands to web elements 。 摘要 Web 提供了一个丰富的开放域环境,具有文本、结构和空间属性。在这个环境中...