[论文解读]FLIN: A Flexible Natural Language Interface for Web Navigation
论文地址:FLIN: A Flexible Natural Language Interface for Web Navigation 。
摘要
AI 助手现在可以通过直接与网页 UI 交互为用户完成任务。但是如果没有持续的再训练,现有的语义解析技术和槽填充技术无法灵活地适应各种不同的网站。
我们提出了 FLIN,一个用于网页导航的自然语言接口,可以将用户命令映射为概念层次的动作(而不是低层次的 UI 动作),进而可以灵活地适应不同的网站,并且处理网站的瞬时性。
我们将这个问题建模成排序问题:给定用户命令和一个网页,FLIN 学习对最相关的导航指令(包括动作和参数值)进行评分。为了训练和测试 FLIN,我们从三个领域的九个热门网站中收集了数据集。我们的结果表明:在给定的领域内,FLIN 能够适应新的网站。
研究背景
AI 个人助手现在可以通过直接与网页 UI 交互完成人类的任务。用户命令 AI ,AI 通过输入、选择项目、点击按钮,以及在不同的网页中进行导航等动作执行人类的命令。这样的解决方案十分吸引人,因为它降低了对第三方 API 的依赖,并且扩展了 AI 助手的能力。本文关注这些系统中的一个关键部件:一个能够将用户命令转换为网页浏览器能够执行的导航命令的自然语言接口。
一个实现这种自然语言接口的方法是直接将自然语言映射为低层次的 UI 动作。在网页中,UI 元素通过串联其 DOM 属性进行嵌入表示。然后,学习一个评分函数或者神经策略以判断哪个 UI 元素能够最好地匹配给定的命令。在 UI 元素的层次进行学习十分高效,但是只在受控制(UI 元素并不随时间变化)或者受限制(单个应用)的环境中有效。这和真实网页的情况是冲突的:(1)网站总是在更新;(2)一个用户可能会让助手在不同网页上执行相同的任务。为了处理网页的瞬时性和多样性,我们需要一个在不经过持续在训练的情况下,能够灵活地适应有着变量和未知行为的环境的自然语言接口。
为了达到这个目标,我们采用两个步骤。首先,我们提出一种为网页导航设计自然语言接口的新方法。我们不将自然语言命令映射为低层次的 UI 操作,而是将它们映射为具有丰富信息的概念层次的动作。概念层次的动作用于表达当用户在看网页 UI 时,他们看到了什么。如图 1 所示:OpenTable 的首页有一个概念层次的动作“Let’s go”(一个搜索按钮),这表示了一个搜索的概念,并且可以通过各种参数进行具体化。直观上来说,同一个领域内的网站会有着语义相似的概念层次动作,并且人类任务的语义不会随着时间变化。因此,在概念层次学习动作,可以得到一个更加灵活的自然语言接口。
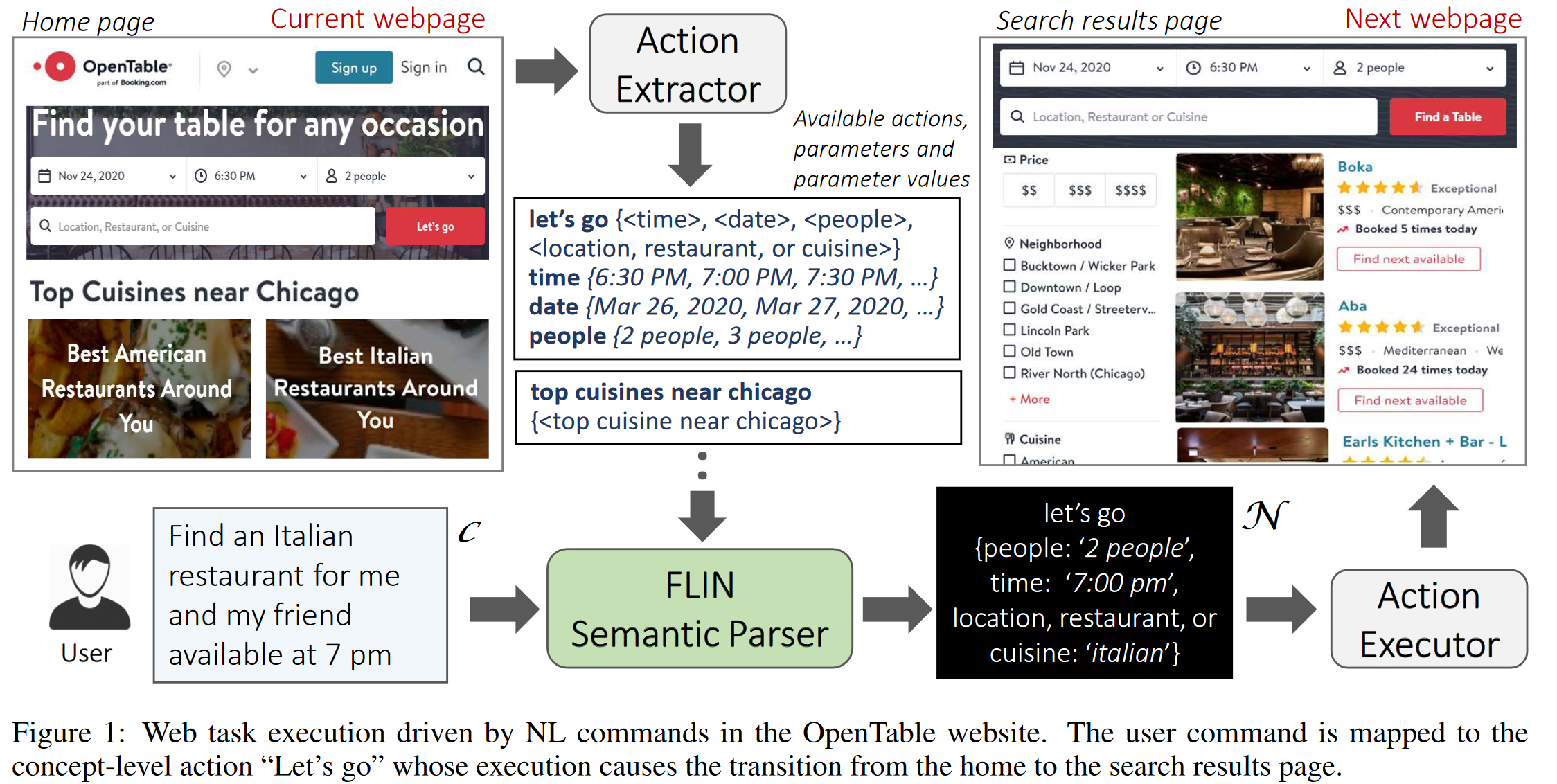
然而,虽然概念层次的动作比原始 UI 元素种类更少,在不同的网站上,它们还是会有不同的表现形式和不同的参数。例如:在 opentable.com 上搜索餐馆,对应的是“Let’s go”,并且支持多达四个参数;而在 yelp.com 上,对应的是“Search”按钮,并且只支持两个参数。并且同一个领域的网站,也会有不同种类的动作(如搜索餐馆和点外卖)。
我们解决问题的第二步是采用了一种新的语义解析方法。传统的语义解析方法是用于处理有着固定且已知的动作的环境,不能直接使用。因此,我们提出了 FLIN,一种新的语义解析方法,其中我们不是学习如何将自然语言命令映射成可执行的逻辑形式,而是利用逻辑形式中符号的语义信息,来学习如何与给定的命令进行匹配。具体地,我们将语义解析任务建模成一个排序问题:给定自然语言命令 和在网页上可执行的动作集合 ,FLIN 根据 为每一个动作打分。同时,对于一个动作的每个参数 ,从 中提取一个可以表达 值的解析 ,然后根据 对 值进行评分,以得到 的最佳评分。每个动作及其相关的参数值列表都表示一个待排序的候选导航指令。FLIN 基于对应动作和参数值分数学习每个指令的网络得分,并且输出得分最高的指令作为预测的导航指令。
为了收集能够训练和测试 FLIN 的数据集,我们构建了一个简单的基于规则的动作提取工具以从网页中提取概念层次的动作及其参数(包括名称和参数值)。如图 1 所示:在一个完整的系统中,我们设想动作提取器提取当前网页中的概念层次动作,并将其传递给 FLIN,FLIN 计算出一个由动作执行器执行的候选导航指令。
文章贡献
总体来看,本文的贡献有三点:
- 基于概念层次的动作,提出了一个为网页导航设计自然语言接口的新方法。
- 我们建立了一个基于匹配的语义解析器,以将自然语言命令映射为导航命令。
- 我们基于九个网站(包括餐饮、旅馆和购物领域)收集了一个新的数据集,并且提供了实证结果,以证明我们方法的泛化性。
代码和数据集开源于:https://github.com/microsoft/flin-nl2web 。
问题描述
假设 是网页 中可行的概念层级动作集合。每个动作 都包含一个动作名称 和一个包含 个参数的集合 。每个参数 都包含一个名字和一个域 (一个可以赋值给参数 的值的集合),这个域可以是封闭域,也可以是开放域。
对于封闭域参数,该域是有限的,并包括了 可以取的一组有限值。这些值是由网页 UI 所规定的,如产品条目可能的颜色和大小,以及一家餐馆可能的预定时间。
对于开放领域参数,原则上该域是无限的,但实际上,它由所有可以从自然语言命令 中提取出来的单词或短语组成。如图 1 所示:动作“let’s go” 的 let’s go, “时间”,“日期”,“人数”,“位置、餐馆或菜肴” 。 这里的前三个参数是封闭域参数,最后一个参数是开放域参数。动作提取模块根据出现在界面中的标签和文本来命名动作和参数(如果不存在标签和文本,就使用 DOM 属性);它还会自动抓取封闭域参数的值(从下拉菜单或者选择列表中)。
在上述设置下,我们的目标是将 中的自然语言命令 映射为一个导航命令 ,其包括一个正确的动作名称 对应动作 ,和一个相关的长度为 的参数赋值列表 。
解决方法
上述的语义解析问题可以被分解成两个子问题:(1)动作识别,即识别 所指示的动作 ;(2)参数识别与赋值,即确定动作的一个参数是否在 中进行表达,如果表达了,那么将值赋给该参数。一个参数是通过被提及(单词或短语)进行表达的。例如:“我和我的朋友”就是参数“人数”的一个“提及”,应当将其解析为值“2 人”。因此,第二个子任务需要首先从 中提取出给定参数的“提及”,然后将其域域值集合进行匹配以找到正确的赋值。对于开放域参数,提取出来的“提及”就是参数的值,而不需要进行匹配。
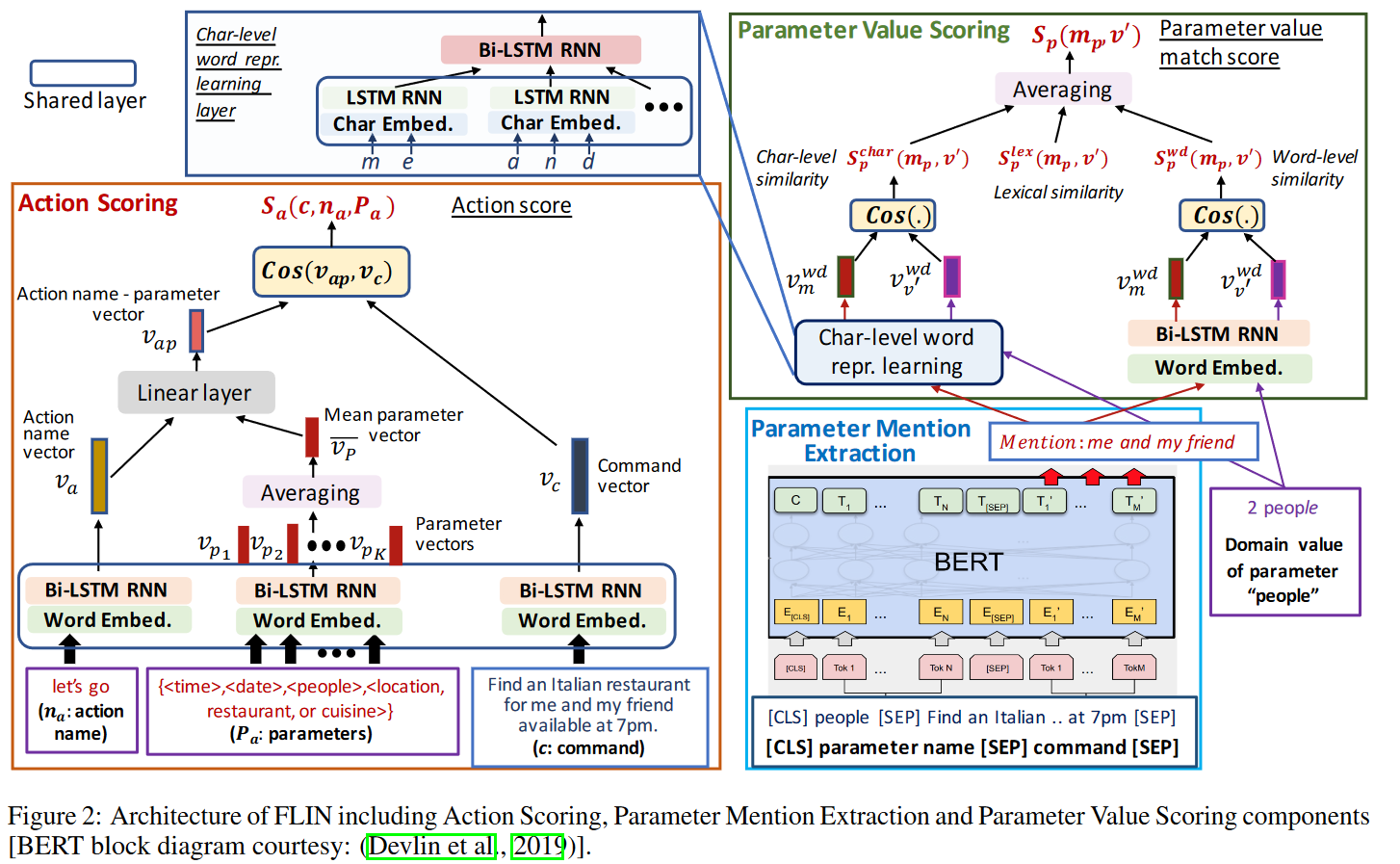
如图 2 所示:FLIN 包括四个组件,以解决前文提到的两个子问题。(1)动作评分,对于给定的命令,为每个可行的操作进行评分。(2)参数提取,从命令中提取给定的参数。(3)参数值评分,使用封闭域参数值为给定的参数打分,如果无法将域值映射到参数,那么就拒绝评分。(4)推理, 使用动作分数和参数值分数推断具有最高分数的“动作-参数-值”分配作为预测的导航指令。
动作评分
给定一个命令 ,为每一个动作 评分以测量 与 的内容的相似性。我们遍历 中的动作及其参数以获得一个(动作名称,参数)对 的列表,然后基于 为它们打分。
为了给每对 打分,我们学习了一个基于神经网络的评分函数 计算其与 的相似度。我们将 表示为 个单词 的序列。为了学习 的向量表示,首先将每个 转换为对应的 one-hot 向量 ,接下来利用一个嵌入矩阵 学习每个单词的嵌入表示 ,其中 是单词词汇表。接下来,给定单词嵌入向量 ,我们使用双向 LSTM 网络(Bi-LSTM)学习其前向和反向表示。假设在输入 处理完毕之后,前向 LSTM 和后向 LSTM 的最终隐藏状态分别为 和 ,就可以这两个状态连接起来,得到 的联合表示 。
接下来,我们学习 的向量表示。对于 ,我们使用相同的嵌入矩阵 和 Bi-LSTM 网络将动作名称 嵌入成向量 。相似地,我们将每个参数 编码成 ,并且将动作 所有参数向量的平均值作为其网络参数语义 。最后,将 和 连接起来,并通过全连接层学习一个联合表示,即:
其中 和 分别是全连接层的权重和偏置。
给定 和 ,利用余弦相似度计算 和 的相似度:
其中 表示向量的第二范数。对于每个 , 。
的损失函数是最小化基于边际的排序目标 ,其目的是使得在 中,每个正 对的分数高于负对的分数,即:
其中 是 中的正 对集合,而 是负 对集合,是通过在 中对动作名称和参数对(不在 中)随机采样得到的。
参数提取
给定一个命令 和一个参数 ,这一步的目标在于正确提取命令 中对 的提及 。具体地,我们希望预测 中表示 的文本。我们将该任务建模成一个问题回答问题,其中 是问题, 是段落,而 就是答案。因此我们通过对 BERT 模型进行微调以解决这个问题。
如图 2 右下角所示,我们将 和 视为一对句子,并且将其以 [CLS] p [SEP] c 的形式打包成一个单独的输入序列,其中 [CLS] 和 [SEP] 是特殊的 BERT token 。对于分词,我们使用标准的 WordPiece 分词器。利用 BERT,我们将序列中的每个 token 输出为 token 。在微调训练的过程中,我们只引入一个提及开始向量 和一个提及结束向量 。单词 是提及的开始的概率通过对 和 应用一个点乘之后在 的所有单词中进行 softmax 操作计算得出: 。结束概率 的计算也通过相似的公式进行。拥有着最高的起始(结束)概率的 ()的位置 ()会被预测为提及的起始(结束)下标, 中对应的 token 会被组合成一个单词序列以提取 。微调训练的目标是最小化正确的起始位置和结束位置的对数似然之和。如果 没有在 中被提及,那么 BERT 会输出 [CLS] 。
参数值评分
在一个封闭域参数 的 被提取出来之后,我们会学习一个基于神经网络的评分函数 ,基于 为 的每个值 评分。如果 是开放域参数,那么就不需要进行评分。
整个过程和动作评分是相似的,但是,出了单词层次的语义相似性,我们还计算了 和 字符层次和词汇层次的相似性。事实上, 和 经常会有部分词汇是匹配的。例如,给定参数“时间”的域值“7:00 PM”,可能的提及为“7 in the evening”、“19:00 hrs”,“at 7 pm” 等等,这些表达中都能够看到部分词汇层次相似性。然而,学习单词层次和字符层次的语义相似性也是十分重要的,因为“PM”和“evening”,以及“7:00PM”和“19:00”这些表达词汇距离很远,但是语义相近。
单词层次的语义相似性 使用与动作评分模块相同的嵌入矩阵 学习 和 的词向量。接下来使用 Bi-LSTM 层(参数不与动作评分模块共享)将提及(值)编码为单词层次的表示向量 (),最后通过如下公式计算 和 的单词层次相似性:
字符层次的语义相似性 使用字符嵌入矩阵 学习组成 和 中单词的每个字符的嵌入向量。为了学习 的字符层次向量表示 ,首先利用 LSTM 网络将字符向量以序列的形式组合起来得到 中每个单词的词向量。在使用 BiLSTM 网络将组成提及的所有单词的词向量组合起来得到 。相似地,也能够得到 的字符层次向量表示 。最后利用如下公式计算 和 的字符层次相似性:
词汇层次的语义相似性 我们使用模糊字符串匹配分数(使用 Levenshtein 距离计算序列之间的差异)和一个自定义的值匹配分数(通过 中出现在 里的单词的比例进行计算)计算词汇层次相似性。接下来我们对这两个相似分数(每个分数 )进行线性组合以得到网络词汇层次相似分数,记为 。
网络值-提及相似分数 定义为以上三个分数的平均值: 。
的优化目标为最小化基于边际的排序目标 。对于一个给定的 ,这个目标希望(提及,正值)对的分数高于(提及,负值)对的分数。其计算方式与前文定义的 的计算方式相同。
推理
推理模块使用动作评分、属性提取和参数值评分模块的输出,为每个 和相关的参数赋值组合列表计算一个网络分数 。接下来使用 预测导航命令。
参数赋值 首先需要推理每个 所应该赋的值。其中,对于封闭域参数 ,预测的值 ,要求 。这里 是一个域值分数(根据经验调整),用于参数值预测。
当在为 进行赋值操作时,我们认为 是 这次赋值的置信分数。如果对于所有的 都有 ,那么我们就认为 的置信分数为 ,这意味着 指向一个 中不存在值,于是 就被舍弃,不进行赋值操作。如果 是一个开放域参数,那么 就会被视为 并且其置信分数为 。
如果在对一个参数化的动作 进行预测时,其所有的 都被舍弃,那么我们就会舍弃 ,因为 不再能够在 中执行。
一旦我们得到了所有参数 的所有赋值的置信分数,我们会将所有置信分数的平均值 作为 的网络参数赋值分数。
导航命令预测 最后,我们通过公式 计算给定的动作 和相关的参数赋值列表的综合分数,其中 是一个根据经验调整的线性组合系数。最后为命令 预测的导航指令就是有着最高的 分数的动作和参数赋值。
实验验证
我们在来自三个具有代表性的领域的九个流行网站上测试了 FLIN 模型:(1)餐饮(R);(2)旅馆(H);(3)购物(S)。我们为每个网站都收集了带标签的数据集,并且进行了同领域跨网站测试。具体地,在每个领域中,我们用一个网站训练 FLIN 模型,并且在其他的两个同领域网站中进行测试。理想情况下,可以用所有三个领域的训练数据训练一个单独的模型,并将其应用到所有的测试网站上。但是我们选择为每个领域专门进行训练/测试以更好地分析 FLIN 模型如何利用概念层次动作的语义重叠(存在于同领域的网站中)泛化到新的网站中。我们舍弃了跨领域的测试,因为在这三个领域中,动作和参数的语义并不明显重叠。
数据集
为了训练和测试 FLIN 模型,我们收集了两个数据集:
- WebNav 包括了英文(命令,导航指令)对。
- DailQueries 包括了从现有的对话数据集中提取出来的英文用户话语和对应的导航指令。
WebNav 数据集
为了收集 WebNav 数据集,给定一个网站和一个它支持的任务,我们首先确定哪些页面和任务相关。然后使用动作提取工具,我们遍历所有和任务有关的页面中的动作。对于每个动作,如果存在,提取器会提供其名称,参数和参数值。动作名称是通过各种 DOM 属性和相关 DOM 元素的文本推测出来的。动作提取的目标是像人类所看到的一样为 UI 元素打上标签。例如,对于 OpenTable 网站,我们不认为搜索框叫做”搜索输入“,而是称之为”地址,餐馆或菜系“(用户看到的搜索框里的占位符)。参数值从 DOM 选择元素(如 option,value 标签)中自动抓取。我们会手动检查动作提取器的输出并更正可能的错误(如动作丢失)。然而,对于每个网站,我们得到了不同的操作/参数方案。在不同的网站之间,类似的动作/参数之间没有一般化的映射,因为构建这样一个映射需要大量的人工工作。表 1 展示了在我们的实验中从所有网站中提取出来的页面、动作和参数的数量。
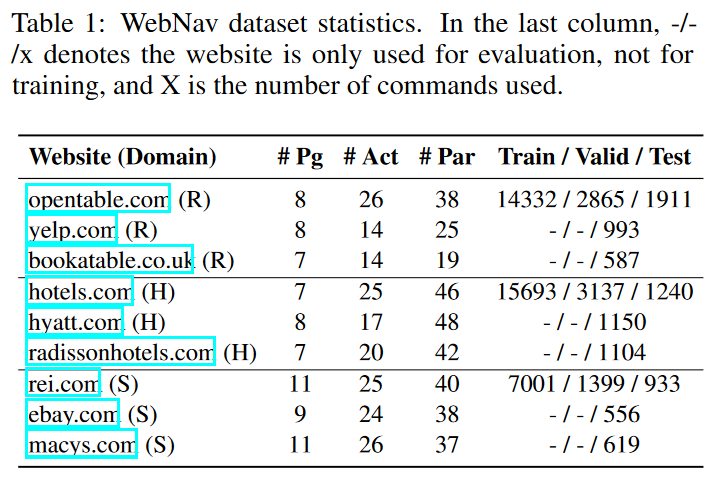
基于这些数据,我们为所有网站上的所有动作构建(页面名称,动作名称,[参数名称])三元组,要求两个注释人员为每个三元组编写多个命令模板,并将参数名称作为占位符(如“预定一个<时间>的餐馆”)。对于封闭域参数,动作提取器自动从网页中抓取参数的值(如 12:00,12:15 等),我们要求注释人员提供相关注释(如“在中午”);对于开放域参数,我们让注释人员提供样例值(如餐厅搜索词的值可以为“pizza”)。我们通过随机化参数值对命令模板进行实例化,以此构建最终的数据集并划分为训练集、验证集和测试集。总体上,我们生成了总共 53520 个(命令,导航指令)二元组。我们分别使用 opentable.com, hotels.com 和 rei.com 三个网站划分训练集和验证集,具体信息如表 1 所示。
DialQueries 数据集
本数据集由从 SGD 对话数据集和 Dialogflow 的餐厅、酒店和购物“预制代理(pre-built agents)”中提取的真实用户请求组成。我们提取出能够映射到我们的网站上任务的请求,并且用词汇表中的等价实体替换了不在词典里的餐厅、旅馆和城市等。我们分别在 opentable.com, hotels.com 和 rei.com 三个网站上人工将 421,155 和 63 条对话请求映射为导航命令。这个数据集只会用于测试。
训练细节
所有的超参数都通过验证集进行调整:
- Batch size 被设置为 50。
- 对于训练轮次,动作评分训练 7 轮,参数提取训练 3 轮,参数值评分训练 22 轮。
- 在每轮训练中,为 随机采样一个负例。
- dropout 概率设置为 0.1。
- 隐藏单元和嵌入向量维度设置为 300。
- 学习率被设置为 。
- 正则化参数为 。
- 。
- 。
- 使用 Adam 优化器。
- 使用 Tesla P100 显卡和 tensorflow 库完成实验。
基线方法
由于相关的方法与本文的方法要么输出类型不同,要么问题设置不同,本文的工作并没有直接的基线方法进行对比。因此,我们将 FLIN 与其两个变体进行对比,它们都使用了基于匹配的语义解析方法,但是仍有不同。
- FLIN-sem 在参数值评分阶段只使用单词层次和字符层次的语义相似性(没有词汇相似性)。
- FLIN-lex 在参数值评分阶段只使用词汇相似性。
评测指标
我们使用准确率(A-acc)评测动作预测性能,平均 F1 分数(P-F1)评测参数预测性能。P-F1 使用测试命令的平均参数精确率和平均参数召回率进行计算。给定一条命令,参数精确率是在预测的指令中,正确预测的参数的比例;召回率是目标指令中,正确预测的参数的比例。对于一条测试命令,如果预测的动作是错误的,或者没有动作被预测,那么我们认为精确率和召回率都为 。
我们还使用以下两个指标:(1)精确匹配准确率(Exact Match Accuracy, EMA),预测指令与目标指令完全匹配的测试命令的百分比;(2)100% 精确率(PA-100),参数精确率为 ,且预测动作是正确的,但是参数召回率 的测试命令的比例。与参数精确率和召回率相似,在计算 EMA 和 PA-100 时,如果预测的动作是错误的,或者没有动作被预测,那么就将 EMA 和 PA-100 视为 。
实验结果
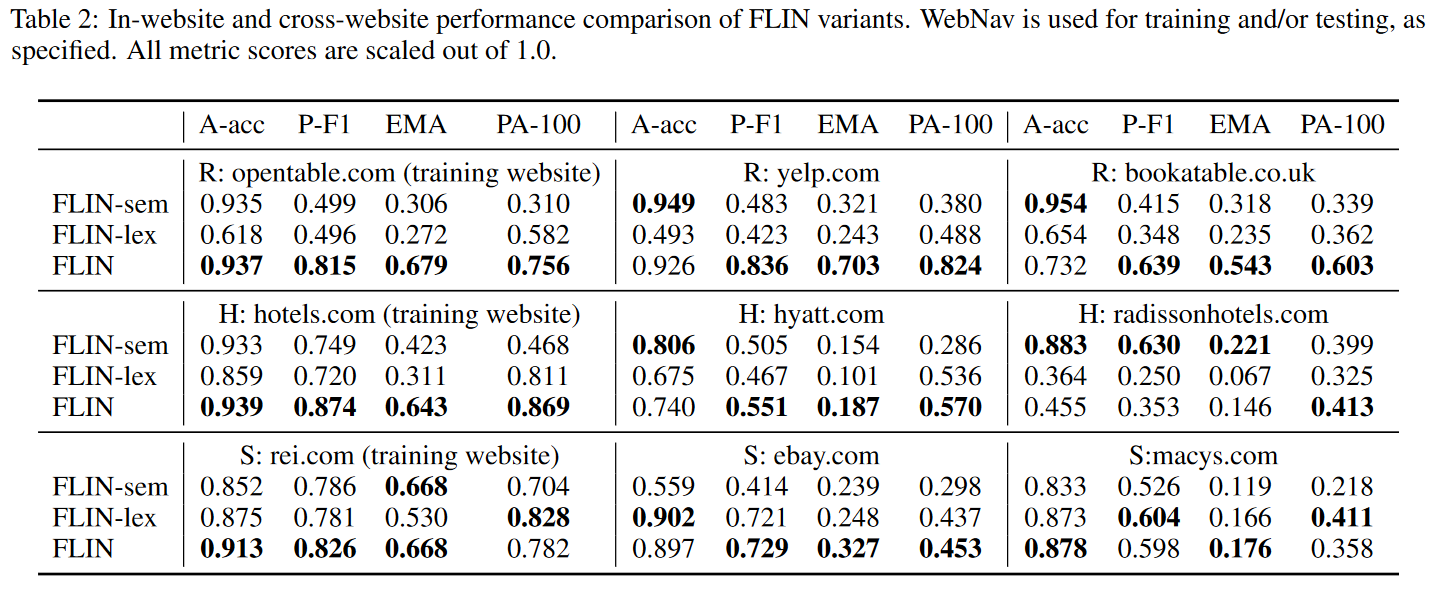
实验结果如表 2 所示。我们测试了同网站(模型的训练和测试使用相同的网站)性能与跨网站(模型的训练和测试使用不同的网站)性能。实验结果解析如下:
- 由于 FLIN 的基于匹配的语义解析方法,FLIN 及其两个变体都能较好地适应到之前没见过的网站。
- FLIN 的总体表现最好,在适应新的网站方面,它能达到与基线相当的(更高的)动作准确率(A-acc)和参数 F1(P-F1)分数。
- 考虑 PA-100 指标,在餐厅领域,训练网站上 的命令,两个测试网站上分别 和 的命令被映射成了正确的可执行动作(没有错误的预测)。在其他两个领域,PA-100 指标总体也比较高。
- EMA 指标比 PA-100 指标更低,因为正确预测所有参数赋值明显更难。
- 考虑 FLIN 的变体,FLIN-sem 和 FLIN-lex 总体上表现不如 FLIN ,因为结合 FLIN 中的词汇和语义相似度可以让参数赋值更加准确,并且更好地泛化。
从泛化的角度来说,最具有挑战性的领域是酒店领域。虽然酒店领域的动作预测准确率(A-acc)为 ,其 EMA 仅为 。下降的主要原因是酒店领域的命令有很多的参数(如入住时间,离店时间,房间数量等),数量明显多余其他两个领域的请求参数数量。而购物领域又会比餐馆领域更具有挑战性,因为在餐馆领域,FLIN 需要处理通过一个相对包含的词汇表与相同实体类型(餐馆)关联起来的动作/参数;而购物产品的范围非常广泛,在不同的网站之间,不同的实体类型会有很多不同的动作/参数。
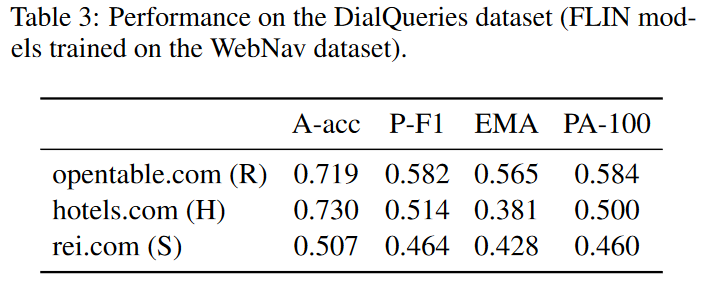
我们还在 DialQueries 数据集的真实用户请求中测试了 FLIN 的效果。如表 3 所示:尽管 FLIN 没有在 DialQueries 数据集上进行训练,总体的 A-acc 指标超过了 ,并且 PA-100 指标也超过了 ,这体现出了 FLIN 在面对新的命令时的鲁棒性。
错误分析
我们随机挑选了 135 条被错误预测的命令(9 个网站,每个网站 15 条),将这些错误分成了 5 种错误类型。如表 4 所示:
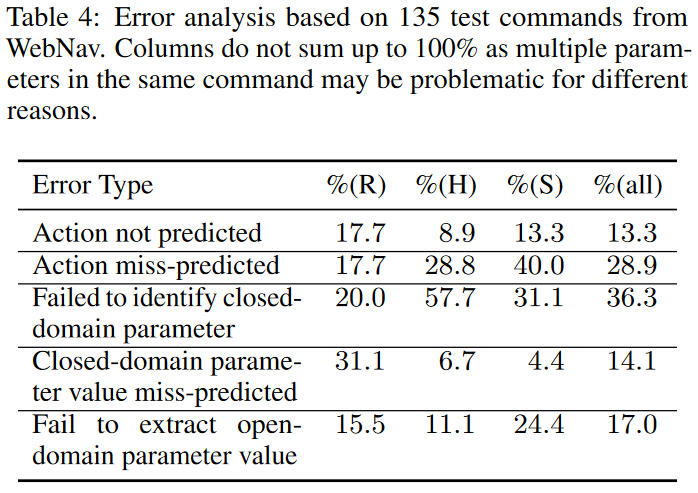
总体看来, 的错误是没有动作被预测(如对于命令“只有八个选择”和基本事实”按 size 过滤{size=8}“,没有任何操作被预测)。 的错误是动作预测错误(预测的动作与目标动作不匹配),主要原因是给定的页面中多个动作有重复的语义。如命令“6个人和2个小孩,纽约的选项”会映射到“选择热门目的地 {destination=new york}”,而不是“寻找酒店{adults=6, children=2, destination=new york}”;以及命令“应用儿童鞋过滤”映射到“根据年龄过滤{gender=kids}”,而不是“根据类别过滤{category=kids footwear}”。
除了错误预测动作以外,在识别封闭域参数方面的错误是最常见的,尤其是在酒店网站和购物网站中。这是因为相较于餐馆网站,这些领域内的网站有更多样的动作和参数空间,这会导致在训练数据中,会有一些动作和参数类型没有被观测到。例如,Hyatt 的搜索动作有特价和用户评分的参数,但是在训练的网站中没有。
为正确识别的封闭域参数预测值的错误通常是由于参数值的形态变化在训练过程中没有被经常观测到(如“晚上 8 点”被映射成“18:00”而不是“20:00”)。
提取开放域参数的错误是由于参数名称过于普遍,提取的参数部分与目标参数匹配,或者有多种格式的参数值。
[论文解读]A Data-Driven Approach for Learning to Control Computers
论文地址:A Data-Driven Approach for Learning to Control Computers 。 摘要 如果机器能够和人类一样使用计算机,进而在每天的任务上都帮助我...
[论文解读]Adversarial Environment Generation for Learning to Navigate the Web
论文地址:Adversarial Environment Generation for Learning to Navigate the Web 。 摘要 学习如何自动在网页中进行导航是一个困难...