[论文解读]DRN: A Deep Reinforcement Learning Framework for News Recommendation
论文地址:DRN: A Deep Reinforcement Learning Framework for News Recommendation 。
研究背景
由于新闻特征与用户偏好特征是不断发生变化的,在线个性化新闻推荐是一个很有挑战性的工作。现在已经有一些个性化新闻推荐的模型,如基于内容的方法、基于协同过滤的方法、混合方法等。但是这些方法存在着以下问题:
- 这些方法只对即时奖励(如点击率等)进行建模,而并不会考虑用户当前的行为对未来的影响。
- 大多数方法只使用用户是否点击推荐的新闻作为模型的反馈,而不会加入其他反馈(如用户离开后回到该系统的时间)。
- 这些方法倾向于推荐相似的新闻,推荐结果的多样性与新颖性较低,从而会使用户感到无聊。
文章贡献
- 提出了在线个性化新闻推荐的强化学习框架,使得系统既可以考虑即时奖励,又可以考虑未来奖励。
- 考虑了用户活跃程度以帮助提高推荐的准确率。相较于只考虑用户的点击标签,这将提供更多的信息。
- 应用了一个更加有效的探索策略:Dueling Bandit Gradient Descent(DBGD),提高了推荐准确率。
- 文章所提出的系统已经在一个商业化的新闻推荐应用中部署并且进行了在线实验,实验结果表明系统的表现十分优秀。
问题描述
给定新闻候选池 ,当一个用户 在时刻 向新闻推荐智能体 发送新闻请求时,为用户筛选出一个列表 ,其中包含了前 个最适合推荐给用户的新闻。
解决方法
提出了一个基于 DQN 的深度强化学习方法以解决在线个性化新闻推荐的问题。
整体框架
如下图所示:整个模型被分成离线部分与在线部分。
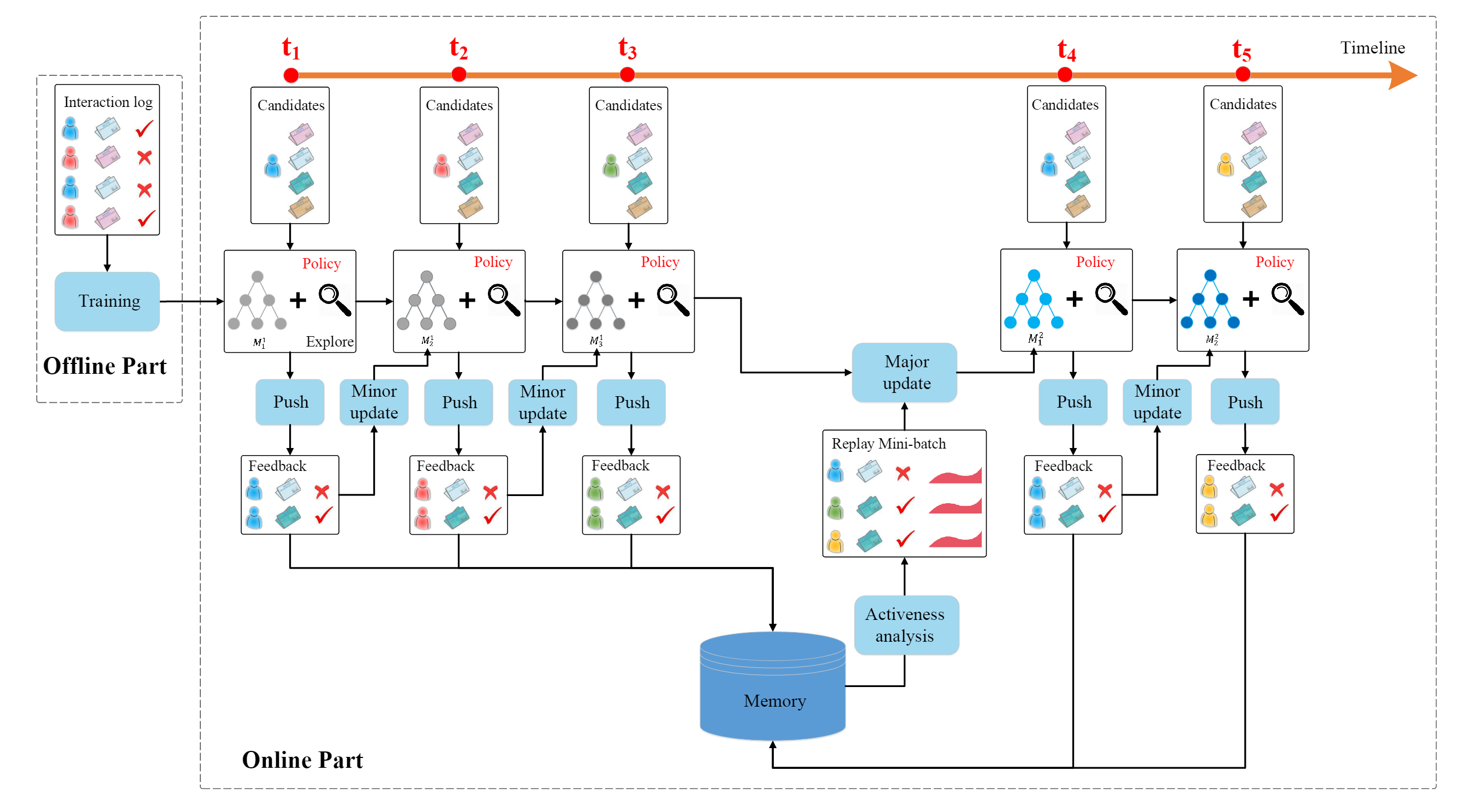
在离线部分,从用户和新闻中提取了四种特征,作为模型的输入。模型利用输入的特征预测奖励(如用户-新闻点击标签与用户活跃程度)。离线模型使用离线的用户-新闻点击标签进行训练。
对于在线部分,新闻推荐智能体 将重复通过以下四个步骤与用户进行互动:
- PUSH: 每当用户向系统发送了一个新闻请求,在线模型 将使用当前用户与候选新闻的特征作为输入,生成一个列表 ,包含 条最值得推荐的新闻。
- FEEDBACK: 在线模型通过用户是否点击推荐的新闻获取反馈。
- MINOR UPDATE: 在每个时刻,获取了前一个用户的特征、新闻列表 与用户反馈 之后,在线模型 将通过对比开发网络 (exploitation network)和探索网络 的推荐表现进行更新。如果 的表现更好,那么就往 的方向更新 网络的参数,否则 的参数将保持不变。
- MAJOR UPDATE: 在一段时间过后,模型 将根据储存在 Memory 中的经验(用户反馈与用户活跃程度)更新开发网络 的参数。
特征提取
输入模型的特征总共可以分成四类:
- 新闻特征:一共有 417 维且采用 one-hot 编码,用于描述某些属性是否出现在新闻中,如:标题、来源、排名、实体名称(entity name)、类别、主题类别等。除此之外,还包括最近 1 小时、6 小时、24 小时、一周和一年的点击量(共 5 维)。
- 用户特征:主要描述的是用户过去 1 小时、6 小时、24 小时、一周和一年内,点击的新闻中含有对应特征的数量。同时对于每一个时间粒度,统计用户在该粒度上的总点击次数。因此总共有 维。
- 用户新闻特征:25 维特征,描述了用户和某一条新闻的交互信息,如新闻中的某个特征(类别、主题类别、来源等)出现在用户历史阅读新闻中的频率。
- 上下文特征:32 维特征,描述了用户请求发生时的上下文信息,如时间、日期、新闻的新鲜度(新闻已发布的时间)等。
一个可以优化的点:加入文本特征(textual feature)的考虑,参考文献:Dynamic Attention Deep Model for Article Recommendation by Learning Human Editors’ Demonstration 。为了专注于深度强化学习模型的分析,本论文未加入该优化。
模型构建
该模型本质上是预测用户点击每一条新闻的概率,因此总体奖励函数如下:
其中:状态 表示为上下文特征和用户特征;动作 表示为新闻特征和用户新闻交互特征; 是当前状态下的奖励(如用户是否点击了新闻); 是智能体对未来奖励的预测。
对于动作的选择,采用 Double DQN 进行动作的选择,其公式如下:
其中: 表示采取动作 能够立刻获得的奖励; 和 分别表示两个 DQN 的参数。
Q 网络的结构如下:
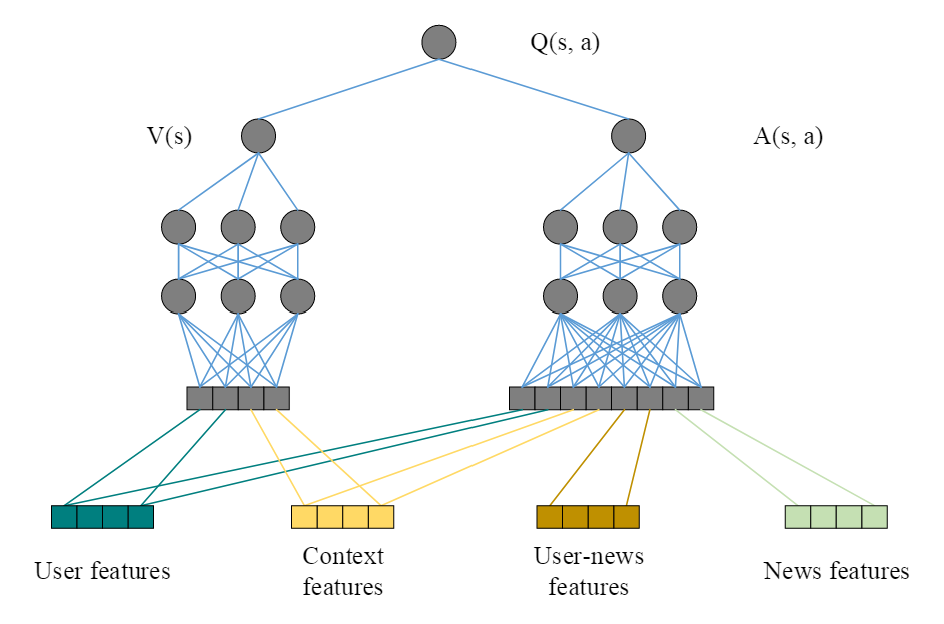
本论文中采用用户特征和上下文特征作为状态特征,用户新闻特征和新闻特征作为动作特征。在模型的预测中:一方面,在状态 下采取动作 的奖励与所有特征都有紧密的关联;另一方面,与用户自身特点(如用户是否活跃,该用户今天的阅读量是否足够)相关的奖励受用户特征和上下文特征影响更大。因此采用类似 Dueling DQN 的思想,将 Q 函数分成价值函数 和优势函数 两部分,其中 只考虑状态特征, 考虑所有特征。
用户活跃度
通常,用户会在一个较短的时间内阅读大量的新闻,在这段时间,他们会以一个极高的频率请求新闻或者点击新闻。然后他们会离开。在若干个小时后,当他们想要阅读更多新闻时,用户又会回到这个新闻 APP 。在点击新闻之前,用户总是会先请求新闻,因此,在这个过程中,用户点击也被隐式地考虑了。
本文使用生存模型来建模用户的返回行为和用户活跃度。假设 是下一个事件发生的时间,那么危险函数(事件发生的瞬时速率)可以被定义为:
因此,时间 之后事件发生的概率为:
因此可以通过如下公式计算生命周期 :
在本问题中,假设 ,即用户返回的概率是固定的。当用户返回之后,令 ,但是用户的活跃程度评分不会超过 。因此用户活跃程度变化会如下图所示:
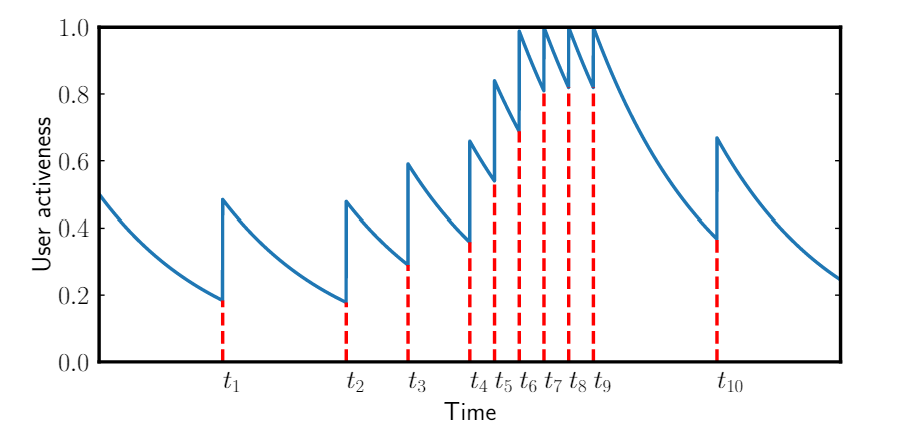
参数 由数据集中的真实用户模式确定。确定方式如下:
- 被设置为 以表示最开始每个用户的活跃状态是随机的。
- 观察发现除了一天多次阅读新闻的行为,用户通常会每天定期返回应用,因此将 设置为 小时。
- 根据 和 可以计算出 为 。
- 为了保证在一个生命周期之后返回的行为会导致活跃值回到初始值,有方程 ,解得 。
最后,点击标签 和用户活跃程度 会通过如下公式结合起来:
其中 是用户活跃系数。这就是最后的奖励函数。
探索过程
由于传统的 贪心算法和 UCB 算法会降低推荐的准确率,因此本文采用了 Dueling Bandit Gradient Descent (DBGD) 算法来进行探索。其总体框架如下图所示:
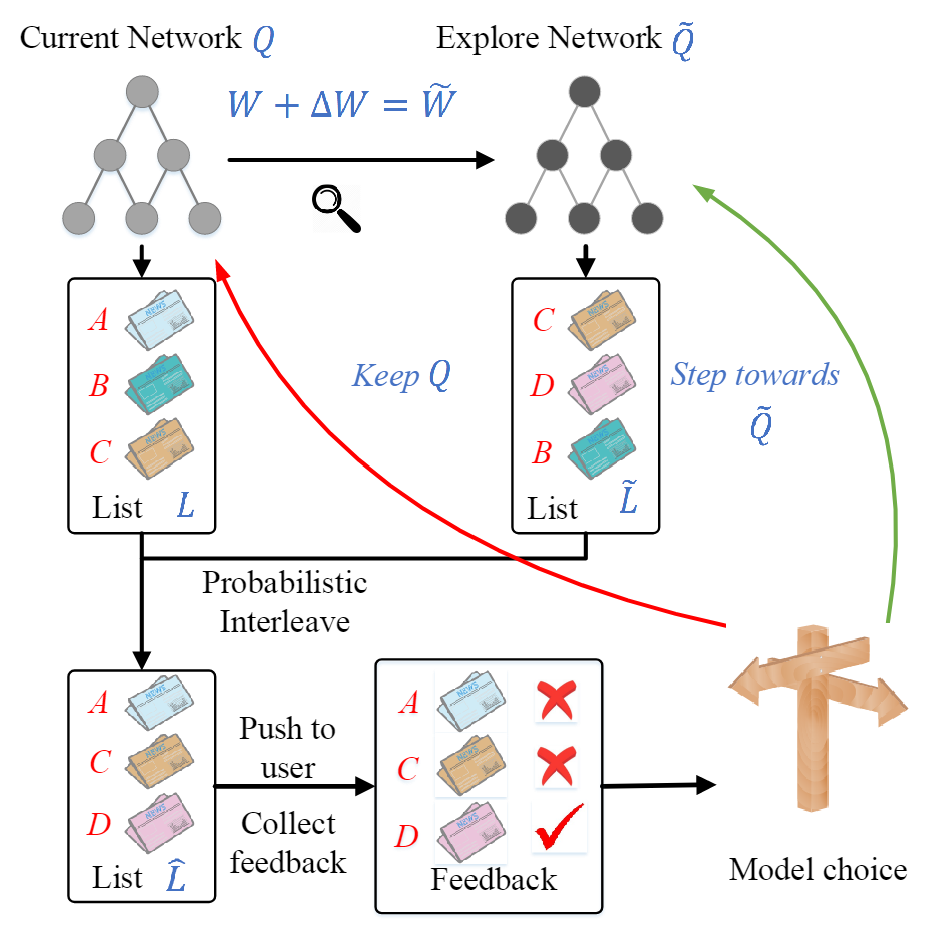
探索过程首先需要构建探索网络 ,其参数 是对原来的 网络的参数进行微小的扰动得到的。这个微小的扰动采用如下方式进行计算:
其中: 是探索系数; 是一个在 到 之间的随机数。接下来就可以通过 计算出探索网络 的参数了。
有了当前网络和探索网络之后,智能体将对两个网络的输出结果进行概率交织(probabilistic interleave)操作,以使用 和 生成最终的推荐结果 。
概率交织操作:首先随机选择 和 中的一个列表,再以由排名决定的概率(排名靠前的新闻有更大的概率被选择)在被选择的列表中随机选择一条新闻。重复上述过程,直到 生成完毕。
最后 会被推荐给用户,并且从用户处获得反馈 。如果由 推荐的新闻获得了更好的反馈,那么就往 的方向更新 网络的参数:
否则, 网络的参数将保持不变。
实验验证
数据集
来源:自家商业新闻 APP 。
收集的数据:用户信息,新闻信息,和用户与新闻的交互信息(点击与否)。
训练集与测试集划分:根据时间顺序划分,以使得在线模型能够学习到序列信息。
在线实验使用离线实验训练好的模型作为预训练模型。
评价指标
一共有三个评价指标。
CTR:用户点击率
Precision@k:
nDCG:标准化折损累计收益(Normalized Discounted Cumulative Gain)。假设 是新闻在推荐列表里面的排名, 是推荐列表的长度, 是排序算法, 是 或 以表示点击是否发生, 是折损函数,那么 nDCG 的计算公式为:
其中:
超参数设置
| 超参数 | 值 |
|---|---|
| 未来收益折损系数 | |
| 用户活跃系数 | |
| 探索系数 | |
| 原始网络更新系数 | |
| 主更新(Major update)周期 | 分钟 |
| 微更新(Minor update)周期 | 分钟 |
对比方法
略